Jak funguje MapReduce?
•
1 like•844 views

Jednostránkový. velmi názorný přehled principů MapReduce. Zakomponován Splunk.

Recommended
More Related Content
More from Kamil Brzak
Jak funguje MapReduce?
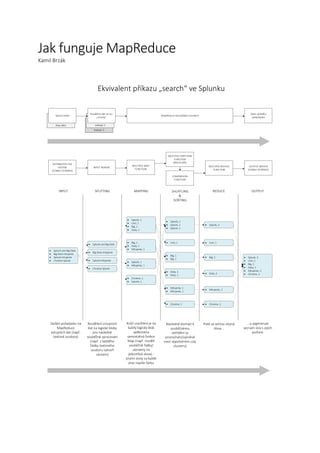
- 1. Jak funguje MapReduce Kamil Brzák Indexer 3 Indexer 2Raw data Splunk umí Big Data Big Data milujeme Splunk milujeme Chceme Splunk Splunk umí Big Data Big Data milujeme Splunk milujeme Chceme Splunk Splunk, 1 Umí, 1 Big, 1 Data, 1 Big, 1 Data, 1 Milujeme, 1 Splunk, 1 Milujeme, 1 Chceme, 1 Splunk, 1 INPUT SPLITTING MAPPING Splunk, 1 Splunk, 1 Splunk, 1 Umí, 1 Big, 1 Big, 1 Data, 1 Data, 1 Milujeme, 1 Milujeme, 1 Chceme, 1 SHUFFLING & SORTING Splunk, 3 Umí, 1 Big, 2 Data, 2 Milujeme, 2 Chceme, 2 REDUCE Splunk, 3 Umí, 1 Big, 2 Data, 2 Milujeme, 2 Chceme, 2 OUTPUT Zadání požadavku na MapReduce vstupních dat (např. textové soubory) Rozdělení vstupních dat na logické bloky pro následné souběžné zpracování (např. z každého řádku textového souboru vytvoří záznam) INPUT READER Kvůli urychlení je na každý logický blok aplikována samostatná funkce Map (např. rozdělí souběžně řádky/ záznamy na jednotlivá slova) - jinými slovy za každé pivo napíše čárku DISTRIBUTED FILE SYSTEM (STABLE STORAGE) MULTIPLE MAP FUNCTION MULTIPLE PARTITION FUNCTION (REDUCERS) COMPARISON FUNCTION MULTIPLE REDUCE FUNCTION Následně dochází k souběžnému setřídění (a promíchání/výměně mezi výpočetními uzly clusteru) Poté se sečtou stejná slova... ...a vygeneruje seznam slov s jejich počtem OUTPUT WRITER (STABLE STORAGE) Splunk index Rozdělení dat na tzv. chunky Ekvivalent příkazu search ve Splunku MapReduce nad každým chunkem Zápis výsledku vyhledávání