RHive tutorial 5: RHive 튜토리얼 5 - apply 함수와 맵리듀스
•
1 gefällt mir•1,642 views

RHive tutorial 5: RHive 튜토리얼 5 - apply 함수와 맵리듀스 (한글판)
![column1
*
10
},
'sepallength')
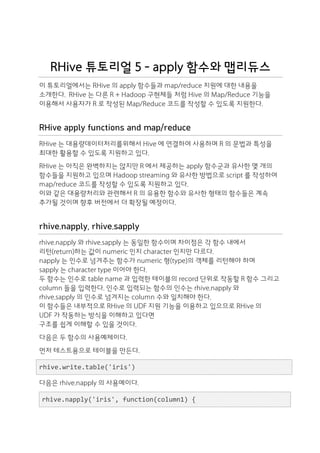
rhive.napply('iris',
function(column1)
{
column1
*
10
},
'sepallength')
[1]
"iris_napply1323970435_table"
rhive.desc.table("iris_napply1323970435_table")
col_name
data_type
comment
1
_c0
double
다음은 rhive.sapply 의 사용예이다.
rhive.sapply('iris',
function(column1)
{
as.character(column1
*
10)
},
'sepallength')
[1]
"iris_sapply1323970891_table"
rhive.desc.table("iris_sapply1323970891_table")
col_name
data_type
comment
1
_c0
string
이 함수들을 사용할 때 주의할 점은 이 함수들은 data.frame 을 리턴하지 않고
함수 내부에서 임시로 만든 table 의 이름을 리턴한다.
사용자는 리턴값으로 함수들이 처리결과로 생성한 테이블들을 재처리하고 지워한다.
이것은 대용량 데이터를 처리하는 할 때는 처리한 결과를 data.frame 으로 받거나
표준출력(standard output)으로 받는 것이 불가능한 경우가 많기 때문이다.
rhive.mrapply, rhive.mapapply, rhive.reduceapply](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
Empfohlen
Empfohlen
Weitere ähnliche Inhalte
Was ist angesagt?
Was ist angesagt? (19)
Ähnlich wie RHive tutorial 5: RHive 튜토리얼 5 - apply 함수와 맵리듀스
Ähnlich wie RHive tutorial 5: RHive 튜토리얼 5 - apply 함수와 맵리듀스 (20)
Mehr von Aiden Seonghak Hong
Mehr von Aiden Seonghak Hong (15)
RHive tutorial 5: RHive 튜토리얼 5 - apply 함수와 맵리듀스
- 1. RHive 튜토리얼 5 - apply 함수와 맵리듀스 이 튜토리얼에서는 RHive 의 apply 함수들과 map/reduce 지원에 대한 내용을 소개한다. RHive 는 다른 R + Hadoop 구현체들 처럼 Hive 의 Map/Reduce 기능을 이용해서 사용자가 R 로 작성된 Map/Reduce 코드를 작성할 수 있도록 지원한다. RHive apply functions and map/reduce RHive 는 대용량데이터처리를위해서 Hive 에 연결하여 사용하며 R 의 문법과 특성을 최대한 활용할 수 있도록 지원하고 있다. RHive 는 아직은 완벽하지는 않지만 R 에서 제공하는 apply 함수군과 유사한 몇 개의 함수들을 지원하고 있으며 Hadoop streaming 와 유사한 방법으로 script 를 작성하여 map/reduce 코드를 작성할 수 있도록 지원하고 있다. 이와 같은 대용량처리와 관련해서 R 의 유용한 함수와 유사한 형태의 함수들은 계속 추가될 것이며 향후 버전에서 더 확장될 예정이다. rhive.napply, rhive.sapply rhive.napply 와 rhive.sapply 는 동일한 함수이며 차이점은 각 함수 내에서 리턴(return)하는 값이 numeric 인지 character 인지만 다르다. napply 는 인수로 넘겨주는 함수가 numeric 형(type)의 객체를 리턴해야 하며 sapply 는 character type 이어야 한다. 두 함수는 인수로 table name 과 입력한 테이블의 record 단위로 작동할 R 함수 그리고 column 들을 입력한다. 인수로 입력되는 함수의 인수는 rhive.napply 와 rhive.sapply 의 인수로 넘겨지는 column 수와 일치해야 한다. 이 함수들은 내부적으로 RHive 의 UDF 지원 기능을 이용하고 있으므로 RHive 의 UDF 가 작동하는 방식을 이해하고 있다면 구조를 쉽게 이해할 수 있을 것이다. 다음은 두 함수의 사용예제이다. 먼저 테스트용으로 테이블을 만든다. rhive.write.table('iris') 다음은 rhive.napply 의 사용예이다. rhive.napply('iris', function(column1) {
- 2. column1 * 10 }, 'sepallength') rhive.napply('iris', function(column1) { column1 * 10 }, 'sepallength') [1] "iris_napply1323970435_table" rhive.desc.table("iris_napply1323970435_table") col_name data_type comment 1 _c0 double 다음은 rhive.sapply 의 사용예이다. rhive.sapply('iris', function(column1) { as.character(column1 * 10) }, 'sepallength') [1] "iris_sapply1323970891_table" rhive.desc.table("iris_sapply1323970891_table") col_name data_type comment 1 _c0 string 이 함수들을 사용할 때 주의할 점은 이 함수들은 data.frame 을 리턴하지 않고 함수 내부에서 임시로 만든 table 의 이름을 리턴한다. 사용자는 리턴값으로 함수들이 처리결과로 생성한 테이블들을 재처리하고 지워한다. 이것은 대용량 데이터를 처리하는 할 때는 처리한 결과를 data.frame 으로 받거나 표준출력(standard output)으로 받는 것이 불가능한 경우가 많기 때문이다. rhive.mrapply, rhive.mapapply, rhive.reduceapply
- 3. 이 함수들은 앞서의 예에서 본 apply 함수들과 비슷한 이름을 가졌지만 실제로는 Hadoop 의 map/reduce 를 Hadoop streaming 을 사용하는 것 같은 형태로 할 수 있게 해주는 함수이다. Hadoop streaming 의 예제에서 흔히 볼 수 있는 wordcount 와 같은 예제들을 RHive 에서는 이 함수들을 이용해서 구현할 수 있으며 전통적인 Map/Reduce style 의 코드를 작성하고 싶어하는 사용자에게 필요한 함수 일 것이다. 이 함수들의 사용법은 아주 쉽다. rhive.mapapply 는 인수로 입력한 table 과 column 들에 대해서 인수로 입력한 function 을 map 으로만 수행해준다. rhive.reduceapply 는 reduce 만을 수행한다. 그리고 rhive.mrapply 는 map 과 reduce 를 모두 수행하게 해준다. map 과정만 필요한 것을 만드려고 한다면 rhive.mapapply 를 사용하고 reduce 과정만 필요한 것을 만드려고 하면 rhive.reduceapply 를 사용하면 된다. 그리고 두 과정이 모두 필요하다면 rhive.mrapply 를 사용하면 된다. 특별한 경우가 아니라면 대부분 rhive.mrapply 를 사용하는 경우가 많을 것이다. 다음 rhive.mrapply 를 이용한 wordcount 의 예이다. 먼저 wordcount 를 적용해 볼만한 데이터셋을 만들자. lynx 라는 text web browser 를 이용해 R introduction page 를 crawling 해서 Hive table 로 저장할 것이다. 우선 lynx 라는 text web browser 를 설치하자. 만약 lynx 를 설치하기 싫고 따로 마련해 놓은 text file 이 있다면 그것을 이용해도 좋다. yum install lynx 다운로드 받은 파일을 Hive table 로 저장한다. # Open R system("lynx -‐-‐dump http://cran.r-‐project.org/doc/manuals/R-‐ intro.html > /tmp/r-‐intro.txt") rintro <-‐ readLines("/tmp/r-‐intro.txt") unlink("/tmp/r-‐intro.txt") rintro <-‐ data.frame(rintro) colnames(rintro) <-‐ c("rawtext") rhive.write.table(rintro) [1] "rintro" rhive.desc.table("rintro")
- 4. col_name data_type comment 1 rowname string 2 rawtext string rintro 라는 text file 에 대해 wordcount 를 수행하는 RHive code 는 다음과 같다. map <-‐ function(key, value) { if(is.null(value)) { put(NA,1) } lapply(value, function(v) { lapply(strsplit(x=v, split=" ")[[1]], function(word) put(word,1)) }) } reduce <-‐ function(key, values) { put(key, sum(as.numeric(values))) } result <-‐ rhive.mrapply("rintro", map, reduce, c("rowname", "rawtext"), c("word","one"), by="word", c("word","one"), c("word","count")) head(result) word count 1 26927 2 " 1 3 "%!%" 1 4 "+") 1 5 "." 1 6 ".GlobalEnv" 3
- 5. 위 예제는 흔히 볼 수 있는 Hadoop streaming 방식(style)의 Map/Reduce 코드와 유사하지만 예제의 마지막 부분에 있는 rhive.mrapply 의 사용법이 사용자에게는 생소할 것이다. RHive 는 Map/Reduce 도 Hive 를 이용해서 처리한다. 때문에 input 이 table name 과 column 을 기본 입력(input) 매개변수(parameter)로 받아야 한다. 그리고 map 과 reduce 의 각 단계별 input 과 output 을 자동으로 알아내는 것이 매우 어렵기 때문에 사용자가 input 과 output 의 개수와 alias 로 사용할 이름들을 알려주어야 한다. 위 예에서의 마지막 구문을 다시 살펴보자. rhive.mrapply("rintro", map, reduce, c("rowname", "rawtext"), c("word","one"), by="word", c("word","one"), c("word","count")) 첫번째 인수인 "rintro" 는 처리(process)할 table 의 이름이다. 바로 뒤에 map 과 reduce 는 각각 map 과 reduce 단계를 처리할 R 함수의 심볼이다. 그 다음 c("rowname", "rawtext")는 map function 의 인수(argument)로 넘겨줄 "rintro" table 의 column 들이며 첫번째는 key 로 사용할 column 이며 두번째는 value 로 사용할 column 이다. 다섯번째 인수인 c("word", "one")은 map 의 output 을 말하고 여섯번째 by="word"는 map 의 output 중에서 aggregation 될 column 을 말한다.그리고 일곱번째와 여덞번째는 각각 reduce 의 input 과 output 이다. 인수의 개수가 많아서 많이 혼동스럽겠지만 Hive 에서 map/reduce 에서 꼭 필여한 것들이다. 이 함수는 향후에 많은 개선이 있을 것이다. rhive.mrapply 는 사실 map/reduce 와 관련된 작업을 내부적으로는 Hive SQL 을 작성하여 처리한다. 이것은 사용자가 rhive.mrapply 를 사용하지 않고도 Hive table 과 RHive 가 지원(provide)하는 함수를 이용해서 이것들을 처리할 수 있음을 의미한다. 하지만 이것또한 다소 난해하고 생소한 구문으로 되어 있어 RHive 에서는 이와같은 함수를 지원하게 된 것이다. rhive.mapapply 와 rhive.reduceapply 는 rhive.mrapply 와 사용법이 거의 같아서 이 튜토리얼에서는 사용법에 대한 설명을 생략한다. 만약 여러분이 기존에 Hadoop streaming 이나 Hadoop library 를 이용한 Map/Reduce 모듈을 가지고 있고 그것을 RHive 로 변환하려 한다면 변환 과정에서 많은 부분에 문제가 발생할 수도 있으며 상당히 많은 코드를 수정해야 할 수도 있다.. RHive 는 Hadoop streaming 을 대체하는 것이 아니며 Hadoop library 를 사용하는 방법을 대체하지 않는다.
- 6. 다만 R 사용자가 R 코드를 작성해서 Hadoop 과 Hive 에 접근하기 쉽도록 돕기위한 효율적인 방법이며 초고성능을 위해서 Map/Reduce 모듈이나 C/C++같은 언어로 작성된 이진실행파일(binary executable file)을 map/reduce 로 변환해서 실행하려고(run) 한다면 여전히 Hadoop library 를 이용해서 구현체를 작성하거나 Hadoop streaming 을 이용하는 방법이 더 나은 선택일 수 있다. 물론 RHive 를 이용해서도 충분히 초고성능의 코드를 작성할 수 있지만 그것은 일반적인 수준의 코드를 작성하는 것과는 달리 Hadoop 과 Hive 에 대한 내부의 작동방식에 대한 고급기술을 필요로 하는 것으로 많은 부분 코드의 설계부터 재구성해야 할 수 있음을 이해하고 있어야 한다.