Machine Learning Tutorial Part - 2 | Machine Learning Tutorial For Beginners ...
Predictive Modelling
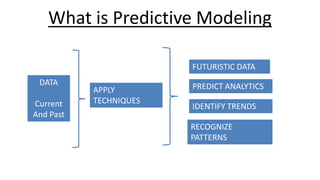
1. What is Predictive Modeling
DATA
Current
And Past
FUTURISTIC DATA
PREDICT ANALYTICS
IDENTIFY TRENDS
RECOGNIZE
PATTERNS
APPLY
TECHNIQUES
2. Predictive Modeling
• Predictive modelling (aka machine learning)(aka pattern
recognition)(...) aims to generate the most accurate estimates
of some quantity or event.
• As these models are not generally meant to be descriptive and
are usually not well–suited for inference.
3. Predictive Modeling
• Statistical Technique - Predictive modeling is a
process used in predictive analytics to create a
statistical model of future behaviour.
• Mathematical Technique - Predictive analytics is the
area of data mining concerned with forecasting
probabilities and trends.
DATA + TECHNIQUE = MODEL
4. How to build a Predictive Model
• Assemble the set of input fields into a dataset
• Example: Age, Gender, Zip Code, Number of Items
Purchased, Number of Items Returned
• This is a vector in a multi-dimensional space as
multiple features are being used to describe the
customer
5. Independent (to be
determined)
Eg: Number of customers
who buy watches as per
gender
Dependent (they are
measured or observed)
Eg: Gender
Types of Variables
6. Independent
Influences the dependent variable
Manipulated by the researcher
Dependent
Affected by changes in the dependent
variable
Not manipulated by the researcher
Difference between variables
7. Control
Controlled by the
researcher
keeping the
values constant in
both the groups
eg: Price of items
Moderating
Studied along
with other
variables eg:
Items returned
Intervening
Can neither be
controlled nor
studied. Its effect
is inferred from
the results. Eg:
behavior
Other types - Extraneous Variables
8. How to build a predictive model Steps
1. Gather data
2. Answer questions
3. Design the structure well
4. Variable Generation
5. Exploratory Data Analysis
6. Variable Transformation
7. Partitioning model set for model build
9. Algorithms
1. Time Series
2. Regression
3. Association
4. Clustering
5. Decision Trees
6. Outlier Detection
7. Neural Network
8. Ensemble Models
9. Factor Analysis
10. Naive Bayes
11. Support Vector Machines
12. Uplift
13. Survival Analysis
11. What is Time Series
1. Review historical data over time
2. Understand the pattern of past behaviour
3. Better predict the future
Set of evenly spaced numerical data
- Obtained by observing response variables at regular time periods
Forecast based only on past values
- Assumes that factors influencing past, present and future will continue
Example: Year 2010 2011 2012 2013 2014
Sales 78.7 93.2 93.1 89.7 63.5
15. Smoothing Methods – Moving Averages
Moving Average = ∑ (most recent n data values)
n
Time Response Moving Total (n = 3) Moving Average (n=3)
2011 4 NA NA
2012 6 NA NA
2013 5 NA NA
2014 3 15 5.00
2015 7 14 4.67
2016 NA 15 5.00
16. Smoothing Methods – Weighted Moving Averages
WMA= ∑ (Weight for period n) (Value in period n)
∑Weights
Month Sales Weights MA WMA
Jan 10.00 1.00
Feb 12.00 2.00
Mar 16.00 3.00
Apr 12.67 13.67
18. Smoothing Methods – Exponential Smoothing
Single Exponential Smoothing
– Similar to single MA
Double (Holt’s) Exponential Smoothing
– Similar to double MA
– Estimates trend
Triple (Winter’s) Exponential Smoothing
– Estimates trend and seasonality
19. Smoothing Methods – Single Exponential Formula
Single exponential smoothing model
Ft+1 = αyt + (1 – α) Ft
Ft+1= forecast value for period t + 1
yt = actual value for period t
Ft = forecast value for period t
α = alpha (smoothing constant)
20. Smoothing Methods – Single Exponential Example
Suppose α = 0.2
Qtr
Sales
Act Forecast from Prior Period Forecast for Next Period
1 23 NA 23
Here Ft= yt since no prior
information exists
2 40 23 (.2)(40)+(.8)(23)=26.4
3 25 26.4 (.2)(25)+(.8)(26.4)=26.296
Ft+1 = αyt + (1 – α) Ft
21. Regression Algorithms
1. Linear Regression
2. Exponential Regression
3. Geometric Regression
4. Logarithmic Regression
5. Multiple Linear Regression
22. Regression Algorithms - Linear
A linear regression line has an equation of the form Y = a + bX,
• X is the explanatory variable
• Y is the dependent variable.
• The slope of the line is b
• a is the intercept (the value of y when x = 0)
• a and b are regression coefficients
23. Regression Algorithms – Linear Example
X Y Y' Y-Y' (Y-Y')2
1.00 1.00 1.21 0.21 0.04
2.00 2.00 1.64 0.37 0.13
3.00 1.30 2.06 0.76 0.58
4.00 3.75 2.49 1.27 1.60
5.00 2.25 2.91 0.66 0.44
MX MY sX sY r
3 2.06 1.581 1.072 0.627
24. Regression Algorithms - Exponential
An exponential regression produces an exponential curve that best fits a single set of data points.
Formula :
(smoothing constant) X (previous act demand) + (1- smoothing constant) X (previous forecast)
1. Suppose you have been asked to generate a demand forecast for a product for year 2012 using an
exponential smoothing method. The forecast demand in 2011 was 910. The actual demand in 2011
was 850. Using this data and a smoothing constant of 0.3, which of the following is the demand
forecast for year 2012?
The answer would be F = (1-0.3)(910)+0.3(850) = 892
2. Use exponential smoothing to forecast this period’s demand if = 0.2, previous actual
demand was 30, and previous forecast was 35.
The answer would be F = (1-0.2)(35)+0.2(30) = 34
25. Regression Algorithms - Geometric
Sequence of numbers in which each term is a fixed multiple of the previous term.
Formula: {a, ar, ar2, ar3, ... }
where:
a is the first term, and
r is the factor between the terms (called the "common ratio")
Example:
2 4 8 16 32 64 128 256 ...
The sequence has a factor of 2 between each number
Each term (except the first term) is found by multiplying the previous term by 2.
222222224888
26. Regression Algorithms - Logarthmic
In statistics, logistic regression, or logit regression, or logit mode is a regression model where
the dependent variable (DV) iscategorical.
Example: Grain
size
Spiders(mm)
0.245 absent
0.247 absent
0.285 present
0.299 present
0.327 present
0.347 present
0.356 absent
0.36 present
0.363 absent
0.364 present
27. Regression Algorithms – Multiple Linear
A regression with two or more explanatory variables is called a multiple regression
222222224888Formula: Y = b 0 + b 1 * 1 + b 2 * 2 + .... + b k * X k + e
Y is the dependent variable (response)
X 1 , X 2 ,.. .,X k are the independent variables (predictors)
e is random error
b 0 , b 1 , b 2 , .... b k are known as the regression coefficients – to be estimated
29. Association Algorithms
• If/ then statements
1. Apriori Example
Transactions Items bought
T1 item1, item2, item3
T2 Item1, item2
T3 Item1, item5
T4 Item1, item2, item5
30. Association Algorithms - ExampleTransaction ID Items Bought
Mango Onion Nintendo Keychains Eggs Yo-Yo Doll Apple Umbrella Corn Ice cream
T1 Yes Yes Yes Yes Yes Yes
T2 Yes Yes Yes Yes Yes Yes
T3 Yes Yes Yes Yes
T4 Yes Yes Yes Yes Yes
T5 Yes Yes Yes Yes Yes
Items Bought Item # transactions Pairs Pairs # transactions Item # trans
OKE 3
{M,O,N,K,E,Y} M 3 MO MO 1 KEY 2
{D, O, N, K, E, Y } O 3 MK MK 3 STEP6
{M, A, K, E} N 2 ME ME 2
{M, U, C, K, Y } K 5 MY MY 2
{C, O, O, K, I, E} E 4 OK OK 3
U 3 OE OE 3
STEP1 D 1 OY OY 2
U 1 KE KE 4
A 1 KY KY 3
C 2 EY EY 2
I 1
STEP2 STEP3 STEP4
STEP5
31. Clustering Algorithms - Definition
• Finding a structure in a collection of unlabeled data.
• The process of organizing objects into groups whose
members are similar in some way.
• Collection of objects which are “similar” between them
and are “dissimilar” to the objects belonging to other
clusters.
36. Clustering Algorithms – Fuzzy C Means
• Allows degrees of membership to a cluster
• 1. Choose a number c of clusters to be found (user input).
• 2. Initialize the cluster centers randomly by selecting n data points
• 3. Assign each data point to the cluster center that is closest to it
• 4. Compute new cluster centers as the mean vectors of the assigned
data points. (Intuitively: center of gravity if each data point has unit
weight.)
• Repeat 3 and 4 until clusters centers do not change anymore.
37. Clustering Algorithms – Hierarchical ClusteringBOS NY DC MIA CHI SEA SF LA DEN BOS/NY/DC MIA CHI SEA SF LA DEN BOS/NY/DC
/
MIA SEA SF/LA DEN
BOS 0 206 429 1504 963 2976 3095 2979 1949 BOS/NY/DC 0 1075 671 2684 2799 2631 1616
NY 206 0 233 1308 802 2815 2934 2786 1771 MIA 1075 0 1329 3273 3053 2687 2037 CHI
DC 429 233 0 1075 671 2684 2799 2631 1616 CHI 671 1329 0 2013 2142 2054 996 BOS/NY/DC
/CHI
0 1075 2013 2054 996
MIA 1504 1308 1075 0 1329 3273 3053 2687 2037 SEA 2684 3273 2013 0 808 1131 1307 MIA 1075 0 3273 2687 2037
CHI 963 802 671 1329 0 2013 2142 2054 996 SF 2799 3053 2142 808 0 379 1235 SEA 2013 3273 0 808 1307
SEA 2976 2815 2684 3273 2013 0 808 1131 1307 LA 2631 2687 2054 1131 379 0 1059 SF/LA 2054 2687 808 0 1059
SF 3095 2934 2799 3053 2142 808 0 379 1235 DEN 1616 2037 996 1307 1235 1059 0 DEN 996 2037 1307 1059 0
LA 2979 2786 2631 2687 2054 1131 379 0 1059
After merging DC with BOS-NY: (3) After merging CHI with BOS/NY/DC: (5)
DEN 1949 1771 1616 2037 996 1307 1235 1059 0
After merging BOS with NY: (2)
BOS/ MIA CHI SEA SF/L
A
DEN BOS/NY/DC
/CHI
MIA SF/LA/SEA DEN
BOS/NY DC MIA CHI SEA SF LA DEN BOS/NY/DC
/CHI
0 1075 2013 996
BOS/NY 0 223 1308 802 2815 2934 2786 1771 NY/DC MIA 1075 0 2687 2037
DC 223 0 1075 671 2684 2799 2631 1616 BOS/NY/DC 0 1075 671 2684 2631 1616 SF/LA/SEA 2054 2687 0 1059
MIA 1308 1075 0 1329 3273 3053 2687 2037 MIA 1075 0 1329 3273 2687 2037 DEN 996 2037 1059 0
CHI 802 671 1329 0 2013 2142 2054 996 CHI 671 1329 0 2013 2054 996
After merging SEA with SF/LA: (6)
SEA 2815 2684 3273 2013 0 808 1131 1307 SEA 2684 3273 2013 0 808 1307 BOS/NY/DC
/CHI/DEN
MIA SF/LA/SEA BOS/NY/DC
/CHI/DEN/S
F/LA/SEA
MIA
SF 2934 2799 3053 2142 808 0 379 1235 SF/LA 2631 2687 2054 808 0 1059 BOS/NY/DC
/CHI/DEN
0 1075 1059 BOS/NY/D
C/CHI/DE
N/SF/LA/S
EA
0 1075
LA 2786 2631 2687 2054 1131 379 0 1059 DEN 1616 2037 996 1307 1059 0 MIA 1075 0 2687 MIA 1075 0
DEN 1771 1616 2037 996 1307 1235 1059 0
After merging SF with LA: (4)
SF/LA/SEA 1059 2687 0
After merging DEN with BOS/NY/DC/CHI: (7)
After merging SF/LA/SEA with BOS/NY/DC/CHI/DEN:
(8)
38. Clustering Algorithms – Probabilistic Clustering
• Gaussian mixture models (GMM) are often used
for data clustering.
• A probabilistic model that assumes all the data points
are generated from a mixture of a finite number of
Gaussian distributions with unknown parameters
39. Decision Tree Algorithms
• A decision tree is a structure that divides a large
heterogeneous data set into a series of small
homogenous subsets by applying rules.
• It is a tool to extract useful information from the
modeling data
All
Data
Designer Watches > 5000
Wallets > 1000
Jewellery > 10000
Bags > 5000
Males
Age > 20
Females
Age > 20
40. Outlier Detection Algorithms
An outlier is an observation that lies an abnormal distance from other values in a random
sample from a population.
The data set of N = 90 ordered observations as shown below is examined for outliers:
30, 171, 184, 201, 212, 250, 265, 270, 272, 289, 305, 306, 322, 322, 336, 346, 351, 370, 390, 404, 409, 411, 436, 437,
439, 441, 444, 448, 451, 453, 470, 480, 482, 487, 494, 495, 499, 503, 514, 521, 522, 527, 548, 550, 559, 560, 570, 572,
574, 578, 585, 592, 592, 607, 616, 618, 621, 629, 637, 638, 640, 656, 668, 707, 709, 719, 737, 739, 752, 758, 766, 792,
792, 794, 802, 818, 830, 832, 843, 858, 860, 869, 918, 925, 953, 991, 1000, 1005, 1068, 1441
The computations are as follows:
• Median = (n+1)/2 largest data point = the average of the 45th and 46th ordered points = (559 + 560)/2 = 559.5
• Lower quartile = .25(N+1)th ordered point = 22.75th ordered point = 411 + .75(436-411) = 429.75
• Upper quartile = .75(N+1)th ordered point = 68.25th ordered point = 739 +.25(752-739) = 742.25
• Interquartile range = 742.25 - 429.75 = 312.5
• Lower inner fence = 429.75 - 1.5 (312.5) = -39.0
• Upper inner fence = 742.25 + 1.5 (312.5) = 1211.0
• Lower outer fence = 429.75 - 3.0 (312.5) = -507.75
• Upper outer fence = 742.25 + 3.0 (312.5) = 1679.75
41. Neural Networks
• a “connectionist” computational system
• a field of Artificial Intelligence (AI)
• Kohonen self-organising networks
• Hopfield Nets
• BumpTree
42. Ensemble Models
• Monte Carlo Analysis
Task Time Estimate
months
Min
month
Most Likely
month
Max
months
1 5 4 5 7
2 4 3 4 6
3 5 4 5 6
14 11 14 19
Time Months # of Times out of 500 Percentage of Total (rounded)
12 1 0
13 31 6
14 171 34
15 394 79
16 482 96
17 499 100
18 500 100
43. Factor Analysis
• Data reduction tool
• Removes redundancy or duplication from a set of
correlated variables
• Represents correlated variables with a smaller set of
“derived” variables.
• Factors are formed that are relatively independent of
one another.
• Two types of “variables”: – latent variables: factors –
observed variables
45. Naive Bayes Theorem Example
In Orange County, 51% of the adults are males. (It doesn't take too much
advanced mathematics to deduce that the other 49% are females.) One adult is
randomly selected for a survey involving credit card usage.
a. Find the prior probability that the selected person is a male.
b. It is later learned that the selected survey subject was smoking a cigar. Also,
9.5% of males smoke cigars, whereas 1.7% of females smoke cigars (based on
data from the Substance Abuse and Mental Health Services Administration).
Use this additional information to find the probability that the selected
subject is a male
46. Naive Bayes Theorem Solution
M = Male
C = Cigar Smoker
F = Female
N = Non Smoker
P (M) = 0.51 as 51% are smokers
P (F) = 0.49 as 49% are females
P (C/M) = 0.095 because 9.5% of males smoke cigars
P (C/F) = 0.017 because 1.7% of females smoke cigars
So P (M/C) = 0.51 . 0.095
_____________________
0.51 . 0.095 + 0.49 . 0.017
= 0.853
48. Uplift Modelling
• How is it related to Individual’s behaviour?
• When can we use it as a solution?
• Predict change in behaviour
P T (Y | X1, . . . , Xm) − P C (Y | X1, . . . , Xm)
49. Survival Analysis
Christiaan Huygens' 1669 curve showing how
many out of 100 people survive until 86 years.
From: Howard Wainer STATISTICAL GRAPHICS: Mapping the Pathways
of Science. Annual Review of Psychology. Vol. 52: 305-335.
50. Examples to be solved
Baye’s Theorems
1. A company purchases raw material from 2 suppliers A1 and A2. 65% material comes from
A1 and the rest from A2. According to inspection reports, 98% material supplied by A1 is good
and 2% is bad. The material is selected at random and was tried on machine for processing.
The machine failed because the material selected was bad or defective. What is the probability
that it was supplied by A1?
2. The chance that Dr. Joshi will diagnose the disease correctly is 60%. The chance that the
patient will die by his treatment after correct diagnosis is 40% otherwise 65%. A patient
treated by the doctor has died. What is the probability that the patient will was diagnosed
correctly?
3. A consultancy firm has appointed three advisors A,B and C. They have advised 500
customers in a week. A has advised 200, B has advised 180 and C has advised 120. Advisor
A being reported popular, 90% of the customers benefit from his advice. Corresponding
figures for B and C are 80% and 75%. After a week a customer was selected at random and
was found he was not benefitted. What is the probability he was advised by B?
51. Answers Bayes Theorem
1. A company purchases raw material from 2 suppliers A1 and A2. 65% material comes from
A1 and the rest from A2. According to inspection reports, 98% material supplied by A1 is
good and 2% is bad. Corresponding figures for supplier A2 and A1 are 95% and 5%. The
material is selected at random and was tried on machine for processing. The machine
failed because the material selected was bad or defective. What is the probability that it
was supplied by A1?
Substitute these values in the formula for Bayes Theorem
P(A1) = 0.65 can have two outcome P (G/A1) i.e. 0.98 are good and P(B/A1) i.e. 0.02 are bad
P (G/A1) = P (A1) X P(G/A1) = 0.65 X 0.98 = 0.6370
P (B/A1) = P (A1) X P(B/A1) = 0.65 X 0.02 = 0.013
P(A2) = 0.35 can have two outcome P (G/A2) i.e. 0.95 are good and P(B/A1) i.e. 0.05 are bad
P (G/A2) = P (A2) X P(G/A2) = 0.35 X 0.95 = 0.3325
P (B/A2) = P (A2) X P(B/A2) = 0.05 X 0.35 = 0.0175
52. Examples to be solved
Probability – Survival Analysis
The probability that a 30 year old man will survive is 99% and insurance company offers to sell
such a man a Rs 10,000 1 year term insurance policy at a yearly premium of Rs 110. What is
the company’s expected gain?
Let x be the companies expected gain
X1 = Rs 110 corresponding probability (0.99) P1 man will survive
X2 = Rs 10000 + Rs 110 corresponding probability (0.01) P2
= - 9890
∑ p1 x1 = p 1 x x1 + p2 x2 = 0.01 x 110 + 0.01 (- 9890)
= 108.9 – 98.9 = 10