A Novel Multi- Viewpoint based Similarity Measure for Document Clustering
Poster Final
1. R.I.T B. Thomas Golisano
College of COMPUTING AND INFORMATION SCIENCES
Using the GeX Approach for Approximate Matching on Graph Databases
Gireeshma Bokka Reddy (gr9334@rit.edu)
Advisor: Prof. Carlos R. Rivero
Rochester Institute of Technology
References:
1. F. Mandreoli, R. Martogliaa, W. Penzo Approximating expressive queries on graph-modeled data: The GeX approach.
2. C. Stark, B. Breitkreutz, A. Breitkreutz, M. Tyers,T. Reguly BioGRID: a general repository for interaction datasets.
INTRODUCTION:
Increase in the popularity of social networking
websites has increased the need for graph
databases as relationships between the data
hold an important role here. This project is based
on Approximate Matching using the GEX
Approach on such databases.
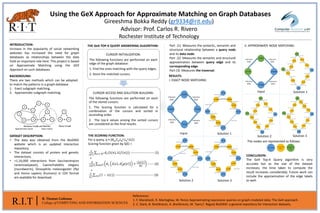
II. APPROXIMATE NODE MATCHING:
CONCLUSION:
The GeX Top-K Query algorithm is very
accurate but as the size of the dataset
increases, the time taken to compute the
result increases considerably. Future work can
include the approximation of the edge labels
as well.
BACKGROUND:
There are two methods which can be adopted
to match the patterns in a graph database
1. Exact subgraph matching.
2. Approximate subgraph matching.
DATASET DESCRIPTION:
• The data was obtained from the BioGRID
website which is an updated interaction
repository.
• The dataset consists of protein and genetic
interactions.
• >1,16,000 interactions from Saccharomyces
cerevisiae(yeast), Caenorhabditis elegans
(roundworm), Drosophila melanogaster (fly)
and Homo sapiens (humans) in CSV format
are available for download.
THE GeX TOP-K QUERY ANSWERING ALGORITHM:
CURSOR INITIALIZATION:
The following functions are performed on each
edge of the graph database:
1. Find the ones matching with the query edges.
2. Store the matched cursors.
CURSOR ACCESS AND SOLUTION BUILDING:
The following functions are performed on each
of the stored cursors:
1. The Scoring function is calculated for a
combination of the cursors and sorted in
ascending order.
2. The top-k values among the sorted cursors
are considered as the final results.
THE SCORING FUNCTION:
For a query, q = (Nq,Eq,LN
q,LE
q,V,C)
Scoring function given by S(Ԑ) =
𝛼
|𝑁 𝑞
| 𝑛 ∈ 𝑁 𝑞 𝑑 𝐿(λ(𝑛), λ(𝑓(𝑛))) ---------------------- (1)
Part (1) Measures the syntactic, semantic and
structural relationship between a query node
and its data node.
Part (2) Measures the semantic and structural
approximation between query edge and its
corresponding edge.
Part (3) Measures the traversal.
Approximate match Exact match
RESULTS:
I. EXACT NODE MATCHING:
Solution 2 Solution 3
Input Solution 1
Input Solution 1
Solution 2 Solution 3
The nodes are represented as follows:
+
𝛽
2 𝐸 𝑞 𝑒∈𝐸 𝑞 𝑑 𝐿 𝜆 𝑒 , 𝜆 𝑔 𝑒 +
𝑐 𝑔 𝑒
𝑀𝐶
------ (2)
+
𝛾
𝐶 𝑐∈𝐶(1 − 𝑠(𝑐)) ------------------------------------ (3)