👉Chandigarh Call Girls 👉9878799926👉Just Call👉Chandigarh Call Girl In Chandiga...
One Way Anova
1. Where are we and where are we going?
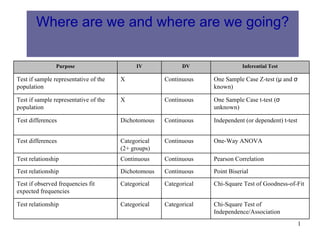
Purpose IV DV Inferential Test
Test if sample representative of the X Continuous One Sample Case Z-test (μ and σ
population known)
Test if sample representative of the X Continuous One Sample Case t-test (σ
population unknown)
Test differences Dichotomous Continuous Independent (or dependent) t-test
Test differences Categorical Continuous One-Way ANOVA
(2+ groups)
Test relationship Continuous Continuous Pearson Correlation
Test relationship Dichotomous Continuous Point Biserial
Test if observed frequencies fit Categorical Categorical Chi-Square Test of Goodness-of-Fit
expected frequencies
Test relationship Categorical Categorical Chi-Square Test of
Independence/Association
1
3. One-Way ANOVA Definition
A One-Way ANOVA is used when comparing two or
more group means on a continuous dependent
variable.
The independent t-test is a special case of the One-
Way ANOVA for situations where there are only two
group means.
3
4. One-Way ANOVA Definition Con’t.
Therefore, if there are only two groups, an
Independent t-test is a shortcut to using a One-Way
ANOVA, but provides the same results. It is an
extension of Independent t-test.
For situations involving more than two groups, a One-
Way ANOVA must be used.
4
5. Types of Variables for One-Way
ANOVA
The IV is categorical. This categorical IV can be
dichotomous (i.e., two groups) or it can have more
than two groups (i.e., three or more groups).
The DV is continuous
Data are collected on both variables for each person
in the study.
5
6. Examples of Research Questions for
One-Way ANOVA
Is there a significant difference among freshmen,
sophomores, and juniors on college GPA? OR Is there
a significant difference in GPA by class level?
Note that GPA is continuous and class standing is
categorical (freshmen, sophomores, or juniors)
Is there a significant difference in student attitudes
toward the course between students who pass or fail a
course?
Note that student attitude is continuous and passing a
course is dichotomous (pass/fail). Because the IV has
only two groups, an independent t-test or rpb could also
be used here.
6
7. Examples of Research Questions for
One-Way ANOVA
Does student satisfaction significantly differ by location
of institution (rural, urban, suburban)?
Note that student satisfaction is continuous and
institution location is categorical.
7
8. More Research Questions
Is there a significant difference in weight loss
when dieting, exercising, and dieting and
exercising?
Is there a significant difference in child’s self-
esteem by parenting style (authoritative,
permissive, and authoritarian)?
Is there a significant difference among those
who condition, blow-dry, or only shampoo in
hair frizziness?
8
9. Why not do multiple t-tests?
Doing separate t-tests inflates Type I
error rate.
An ANOVA controls the overall error by
testing all group means against each
other at once, so your alpha remains at,
for instance .05.
9
10. Why not do multiple t-tests?
We need to compare:
Sample 1 vs. Sample 2
Sample 1 vs. Sample 3
Sample 2 vs. Sample 3
So we need to perform
3 t-tests!
Any experiment with k groups has k X (k-1)/2 different pairs
available for testing.
k=3
k X (3-1) / 2 =
k X 3 (2/2) = 3(1) = 3 different pairs available for testing
10
11. Type I error rate inflate:
Type I Error Rate Inflate
Sample 1 vs. Sample 2 α = .05
Sample 2 vs. Sample 3 α = .05
Sample 2 vs. Sample 3 α = .05
If alpha = .05 for each test, times 3 tests, the new
probability of a Type I error is about 0.15 now!
Type I error rate: 1-(1-α)c
Whereby: α = alpha for each separate t-test
c
= number of t-tests
11
12. Type I error rate inflate:
Type I Error Rate Table
Error rates with repeated t-tests
12
Retrieved from espse.ed.psu.edu/edpsych
13. Assumptions rate inflate:
Type I error
The populations from
which the samples were
obtained must be
normally or
approximately normally
distributed.
The samples must be
independent.
The variances of the
populations must be
equal.
13
14. Major Concepts: Calculating
Sums of Squares
The One-Way ANOVA separates the total variance (hence the
term – analysis of variance) in the continuous dependent variable
into two components: variability between the groups and
variability within the groups.
Variability between the groups is calculated by first obtaining
the sums of squares between groups (SSb), or the sum of the
squared differences between each individual group mean from
the grand mean.
Variability within the groups is calculated by first obtaining the
sums of squares within groups (SSw) or the sum of the squared
differences between each individual score and that individual’s
group mean.
14
15. Major Concepts: Calculating Sums
of Squares
The linear model, conceptually, is: SSt = SSb + SSw, where SSt
is the total sums of squares.
Note the simplicity of statistical models: They are linear
depictions of phenomena, splitting variability into (1) what
we can measure systematically (differences between
groups) and (2) what we can’t explain or account for
systematically (differences within groups).
Variability within the groups is random variance or noise; it
reflects individual differences from the group mean and
sometimes prevents us from seeing difference between
groups.
Variability between the groups is systematic variance, it
reflects differences among the groups due to the experimental
treatment or characteristics of group membership.
15
16. Major Concepts: One-Way
ANOVA as a ratio of variances
Formula for variance:
Σ( x - x ) 2
σ
2
=
N −1
We can see that the numerator is a sum of squared
values (or a sums of squares), and the denominator is
the degrees of freedom. Thus, the formula can be re-
written as:
σ = SS
2
df
16
17. Major Concepts: Variance Components
in ANOVA
The Analysis of Variance (ANOVA) analyzes the ratio of the
variance between groups (i.e., how far apart the group means are
from one another) to the variance within the groups (i.e., how
much variability there is among the scores within a single group).
In ANOVA, these variances, formerly known to us as σ2, are referred
as mean squares (MS) or the average of the sums of squares
(SS/df).
Thus, a mean square between is simply the variance between
groups obtained by a sums of squares divided by degrees of freedom
(SSb/dfb).
Likewise, a mean square within is simply the variance within the
groups also obtained by a sums of squares divided by degrees of
freedom (SSw/dfw). Both are shown below:
SSb SS w
MSb = MSw =
df b df w
17
18. Table 1. Scores and means of the
comparison groups and the total group
Between
Method 1 2 3
1 8 7
4 6 6
3 7 4
2 4 9
5 3 8
1 5 5
6 7
Within 5
Within Within
n 7 6 8
mean 3.14 5.50 6.38
18
20. Major Concepts: Factors that Affect
Significance
The MSb and the MSw are then divided to obtain the F
ratio for hypothesis testing, i.e., F is the ratio of MSb and
the MSw MSb
F=
MS w
As in all statistical tests, the larger the numerator (for
example, the larger the difference between groups), the
larger the test statistic (whether it be r, t, or F), and the
more likely we are to reject the null hypothesis.
Also, the smaller the denominator (the less variability
among people in a group), the larger the test statistic,
and the more likely we are to reject the null hypothesis.
20
21. Major Concepts: Factors that Affect
Significance
The diagrams below show the impact of increasing the numerator of the
test statistic. Note that the within group variability (the denominator of the
equation) is the same in situations A and B. However, the between group
variability is greater in A than it is in B. This means that the F ratio for A will
be larger than for B, and thus is more likely to be significant.
21
22. Major Concepts: Factors that Affect
Significance
The diagrams below show the impact of decreasing the denominator of the
test statistic. Note that the between group variability (the difference
between group means) is the same in situations C and D. However, the
within group variability is greater in D than it is in C. This means that the
F ratio for C will be larger than for D, and thus is more likely to be
significant.
22
23. Major Concepts: t2 = F
Diagrams A through D on the previous slides could also be used to
illustrate the t statistic. As two groups differ more in their means
(increase in numerator and effect size), the larger the value of t
and the more likely we are to find significant results.
The lower the within-group variability (decrease in noise), the
smaller the denominator and the more likely we are to find
significance. This analogy can be made to ANOVA because t is
just a special case of ANOVA when only two groups comprise the
independent variable.
We are familiar with the t distribution as normally distributed (for
large df), with positive and negative values. The F statistic, on the
other hand, is positively skewed, and is comprised of squared
values. Thus, for any two group situation, t2 = F.
23
24. Distribution of F ratio
F distribution is
positively skewed.
If F statistic falls
near 1.0, then
most likely the null
is true.
If F statistic is
large, expect null is
false. Thus,
significant F ratios
will be in the tail of
the F distribution.
24
26. Summary of Calculations
dfb groups = k – 1 where k is # of groups
dfw groups = N – k where N is total # of
individuals in groups
MSb= SSb/ dfb
MSw = SSw/ dfw
*SS isF = MSb/ squared deviations otherwise denoted S
the sum of the MSw 2
26
28. Step 1: State Hypotheses
There is no significant difference among
the groups in variable x.
μ1 = μ2 = μ3 = μ4…
There is a significant difference between
at least two of the groups in variable x. In
other words, at least one mean will
significantly differ.
28
29. Step 2: Set the Criterion for
Rejecting Ho
“Between” (k-1)
“Within”
(N – K)
29
30. Practice with Table C.5, p. 640
3 groups
30 people
df between = k – 1 = 3 – 1 = 2
df within = N – k = 30 – 3 = 27
What is my critical value? Remember, if the
actual value isn’t in the table, use the next
lowest value to be conservative.
30
31. Step 3: Compute Test Statistic
1. Calculate Correction Factor:
(T)2 total scores2
N total number of scores
CF= (sum of each group)2 / total number of observations.
2. Calculate SSB: k = # of groups; n = number of scores
SSB = ∑ TK2 - Correction factor
nk
Sum the total for each group and square / n . Subtract correction factor.
3. Calculate SST: Square each individual score. Sum the squared scores
across all groups and subtract correction factor.
31
32. Step 3: Compute Test Statistic
4. Calculate SS within:
SSW = SST – SSB
5. Calculate MSB and MSW
= SS = SS
K-1
MS df
W
W N-K
MS df
B
B
W B
6. Calculate the F ratio
F = MS B
-------
MS W
32
33. Step 4: Compare Test Statistic to
Criterion
Like t, a large F value
indicates the
difference (or
treatment effect) is
unlikely due to
chance.
When F-ratio is close
to 1.0, it is likely that
the Ho is true.
33
34. Step 5: Make Decision
Fail to reject the null hypothesis and
conclude that there is no significant
difference among the groups F(dfb,dfw) =
insert F statistic, p > insert α.
Reject the null hypothesis and conclude
that there is a significant difference among
the groups F(dfb,dfw) = insert F statistic, p <
insert α.
34
35. Interpreting Tables
Treatment A Treatment B Treatment C
M 2.5 6.0 0.5
SE .43 .58 0.22
N-K K-1 ANOVA Summary SSb/dfb
Source SS df MS F
Between treatments 93 2 46.5 41.02
Within treatments 17 15 1.13 MSb/MSw
Total 110 17 SSw/dfw
N-1 35
36. Suggested Study Cards
Assumptions of ANOVA.
EQUATION FOR ANOVA (slide 16 for
components).
Equation for Type I error rate (alpha
inflation).
Equation for different number of pairs
available for testing.
36