1. Cfare eshte OpenMP ?
“Open specifications for Multi-Processing”
API(Application Programming Interface) per zhvillimin e
applikimeve paralel ne C/C++, Fortran ne arkitektura me
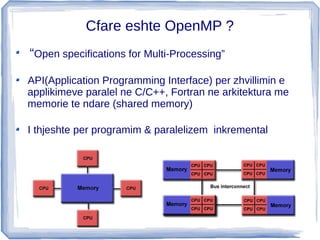
memorie te ndare (shared memory)
I thjeshte per programim & paralelizem inkremental
5. Funksione librarie
Numri i thread-ve
Thread ID
Ndryshimi dinamik i numrit te thread-ve
Parelelizmi i perfshire
Timers
Locking API
6. Variablat e ambientit
Cakton numrin e thread-ve
Tipi i skedulimit
Ndryshimi dinamik i numrit te thread-ve
Parelelizmi i perfshire
7. Rajonet Paralele
Rajoni paralel eshte nje bllok kodi qe ekzekutohet nga
disa thread njekohesisht
#pragma omp parallel [klauzole[[,] klauzole] ...]
{
"ky instruksion do te ekzekutohet paralelisht"
} (barrier)
8. Ushtrim: Hello World (serial)
#include <stdio.h> Kompilimi:
gcc Hello.c -o Hello
void main()
{
Output:
Hello World (0)
int ID = 0;
printf(“Hello World (%d) n“,ID);
}
9. Ushtrim: Hello World (paralel)
#include <stdio.h> Kompilimi:
Direktiva kompilatori te
#include <omp.h> OpenMP
gcc -fopenmp Hello.c -o Hello
void main()
{ Output:
Funksion librarie
#pragma omp parallel i OpenMP Hello World (2)
Hello World (1)
{ Hello World (3)
int ID = 0; Hello World (0)
ID= omp_get_thread_num();
printf(“Hello World (%d) n“,ID);
}
}
10. Klauzolat e OpenMP
Shume direktiva to OpenMP permbajne klauzola
Klauzolat perdoren per te specifikuar informacione shtese
per direktivat
Direktiva te caktuara kane klauzola specifike
11. Klauzolat if/private/shared
if (exp)
- Kodi ekzekutohet ne paralel n.q.s.e exp vleresohet ne “true”
perndryshe ekzekutohet ne serial
private (list)
- Gjithe referencat jane per objektin lokal
- Vlerat jane te papercaktuara ne hyrje dhe dalje te rajonit
paralel
shared (list)
- Te dhenat aksesohen nga te gjithe thread-et
12. Fushpamja e variablave (scoping):
Private ose te ndare (shared)
- Variablat private mund te aksesohen vetem nga thread-i qe i
zoteron ato
- Variablat a ndare mund te aksesohen nga cdo thread
Klauzolat: privat(....)/shared(.....)/default(private|none)
#pragma omp parallel
#pragma omp parallel private(a,c)
#pragma omp parallel default(private), shared(a,b)
#pragma omp parallel default(none), shared(a,b,c)
13. Shembuj me fushpamje variablash :
int x=1;
2 3
#pragma omp parallel shared(x) num_threads(2) 3 2
{ 3 3
x++; printf(“%dn”,x);
}
printf(“%dn”,x);
int x=1;
#pragma omp parallel private(x) num_threads(2)
printon cdo gje
{
x++; printf(“%dn”,x); ne fund printon
} 1
printf(“%dn”,x);
14. Konstruktet e ndarjes se punes
direktiva - sections
direktiva - for
#pragma omp sections direktiva - single
#pragma omp for {
{ #pragma omp single
for(i=0;i<N;i++) #pragma omp section {
a[i]=a[i]+1; { ....
} …code section1 }
}
#pragma omp section
{
…code section2
}
}
Puna (kodi) ndahet ndermjet thread-ave
- keto direktiva duhet te perfshihen brenda rajoneve paralele
- barrier e nenkuptuar (implicite) ne dalje
- konstruktet e ndarjes se punes nuk krijone thread-e te reja
15. Direktiva - for
#pragma omp for [clause …]
Sherben per paralelizimin e ciklit for
int a[N],i;
…...
#pragma omp parallel
{
….....
#pragma omp for
for(i=0;i<N;i++)
a[i]=a[i]+1;
}
16. Direktiva - for
#pragma omp for [clause …]
Sherben per paralelizimin e ciklit for
int a[N],i;
…...
#pragma omp parallel
{
….....
#pragma omp for jo cdo loop for mund te paralelizohet
for(i=0;i<N;i++) duhet te kemi pavaresi te iteracioneve
a[i]=a[i]+1; for(i=1;i<N;i++)
a[i]=a[i-1]+1;
}
17. Ushtrim: mbledhje vektoresh
#include <omp.h>
#define N 10
int main(void) {
float a[N], b[N], c[N];
int i, TID, nthreads;
omp_set_num_threads(4);
#pragma omp parallel default(none), private(i), shared(a,b)
{
#pragma omp for
for (i = 0; i < N; i++) {
a[i] = (i+1) * 1.0;
b[i] = (i+1) * 2.0;
}
}
#pragma omp parallel default(none), private(i,TID), shared(a,b,c,nthreads)
{
TID = omp_get_thread_num();
if (TID == 0) {
nthreads = omp_get_num_threads();
printf("Number of threads = (%d) n",nthreads);
}
printf("Thread %d starting n",TID);
#pragma omp for
for (i = 0; i < N; i++) {
c[i] = a[i] + b[i];
printf("%d, %d, %f, %f, %f n",TID,i+1,a[i], b[i],c[i]);
}
}
}
19. Paralelizimi i cikleve for
Hapat e pergjithshem qe duhen ndjekur
- gjej ciklet for me intensive nga ana llogaritese
- konverto keto ne cikle me iteracione te pavarur
- vendos direktiven e duhur OpenMP ne pozicionin e duhur
int i, j, A[MAX]; int i, A[MAX];
j = 5; #pragma omp parallel for
for (i=0;i< MAX; i++) { for (i=0;i< MAX; i++) {
j +=2; int j =5+2*i;
A[i] = big(j); A[i] = big(j);
} }
20. Klauzola reduction
reduction ( operator :
list )
Variabli ku aplikohet kjo direktive duhet te jete i deklaruar
shared
Perdoret kur vlera e variablit akumulohet brenda nje cikli for
(operatoret : +, *, -, /, &, ^, |, &&, ||)
Nje kopje e variablit krijohet e inicializohet per cdo thread
Ne perfundim te rajonit ose konstruktit , applikohet opeatori
mbi te gjithe variablat private te threade-ve dhe rezultati ruhet
ne variablin a ndare (shared)
…...
int a[n],b[n],results;
…..initialization of a,b
…..........
#pragma omp parallel for default(shared) private(i) reduction(+:result) {
for (i=0; i < n; i++)
result = result + (a[i] * b[i]);
}
printf("Final result= %fn",result);
21. Klauzola Schedule (ne direktiven for)
Kjo direktive percakton si ndahen iteracionet e ciklit for
ndermjet thread-ve
schedule(static [,chunk])
- i ndan iteracionet ne bloqe me permase “chunk” dhe ai cakton
threadeve ne kohen e kompilimit
schedule(dynamic[,chunk])
– c'do thread-i i caktohet ne kohen e ekzekutimi nje bllok me permase
“chunk” nga nje “queue” kur thread perfundon bllokun e caktuar
terheq nje blook tjeter nga “queue”
schedule(guided[,chunk])
– Njesoj si “dynamic” vetem se permasa e blloqeve zvogelohet me
vazhdimin e perpunimit te blloqeve
schedule(runtime)
– tipi i skedulimit dhe “chunk” merren nga variabli i ambientit
OMP_SCHEDULE
22. Direktiva sinkronizimi
OpenMP ofron disa mekanizma sinkronizimi
- barrier (sinkronizon gjithe thread-at ne nje pozicion te kodit)
- master (vetem thread (master) kryesor ekzekuton bllokun)
- critical (vetem nje thread ne kohe ekzekuton bllokun)
- atomic (njesoj si critical por vetem per nje variabel)
24. Ushtrime
a)nderto nje program qe llogarit shumezimin scalar te
dy vektoreve(dot product) ne OpenMP duke mos
perdorur klauzolen reduce dhe me pas duke e
perdorur ate
b) Shkruaj fillimisht nje program serial ne C qe gjen
dhe shfaq ne ekran maximumin e nje vektori me
numer te madh elementesh (~10000)
- Programin me siper paralelizojeni ne disa thread-e
me OpenMP dhe masni sa eshte speedup-i (perfitimi
ne kohe ne krahasim me versionin serial)
- Perdorni funksionet e librarise per matjen e kohes
c) shkruaj nje program serial dhe pastaj ne paralel qe
gjen dhe shfaq maximumin a elementeve te dy
matricave