Poster Simply Targeting (HI DEFINITION)
•
0 gefällt mir•197 views

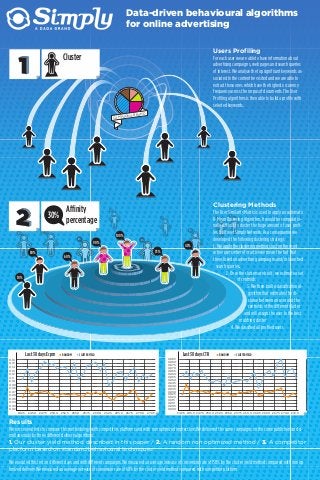
Data-driven behavioural algorithms for online advertising Users Profiling Cluster For each user we are able to have information about advertising campaigns, web pages and search queries of interest. We analyze the top significant keywords as- sociated to the content he visited and we are able to extract those ones which have the highest occurency frequency across the corpus of documents. The User Profiling algorithms is then able to build a profile with selected keywords.
Melden
Teilen
Melden
Teilen
Downloaden Sie, um offline zu lesen
Empfohlen
Empfohlen
VVVIP Call Girls In Greater Kailash ➡️ Delhi ➡️ 9999965857 🚀 No Advance 24HRS Live
Booking Contact Details :-
WhatsApp Chat :- [+91-9999965857 ]
The Best Call Girls Delhi At Your Service
Russian Call Girls Delhi Doing anything intimate with can be a wonderful way to unwind from life's stresses, while having some fun. These girls specialize in providing sexual pleasure that will satisfy your fetishes; from tease and seduce their clients to keeping it all confidential - these services are also available both install and outcall, making them great additions for parties or business events alike. Their expert sex skills include deep penetration, oral sex, cum eating and cum eating - always respecting your wishes as part of the experience
(07-May-2024(PSS)VVVIP Call Girls In Greater Kailash ➡️ Delhi ➡️ 9999965857 🚀 No Advance 24HRS...
VVVIP Call Girls In Greater Kailash ➡️ Delhi ➡️ 9999965857 🚀 No Advance 24HRS...Call Girls In Delhi Whatsup 9873940964 Enjoy Unlimited Pleasure
Falcon stands out as a top-tier P2P Invoice Discounting platform in India, bridging esteemed blue-chip companies and eager investors. Our goal is to transform the investment landscape in India by establishing a comprehensive destination for borrowers and investors with diverse profiles and needs, all while minimizing risk. What sets Falcon apart is the elimination of intermediaries such as commercial banks and depository institutions, allowing investors to enjoy higher yields.Falcon Invoice Discounting: The best investment platform in india for investors
Falcon Invoice Discounting: The best investment platform in india for investorsFalcon Invoice Discounting
Weitere ähnliche Inhalte
Kürzlich hochgeladen
VVVIP Call Girls In Greater Kailash ➡️ Delhi ➡️ 9999965857 🚀 No Advance 24HRS Live
Booking Contact Details :-
WhatsApp Chat :- [+91-9999965857 ]
The Best Call Girls Delhi At Your Service
Russian Call Girls Delhi Doing anything intimate with can be a wonderful way to unwind from life's stresses, while having some fun. These girls specialize in providing sexual pleasure that will satisfy your fetishes; from tease and seduce their clients to keeping it all confidential - these services are also available both install and outcall, making them great additions for parties or business events alike. Their expert sex skills include deep penetration, oral sex, cum eating and cum eating - always respecting your wishes as part of the experience
(07-May-2024(PSS)VVVIP Call Girls In Greater Kailash ➡️ Delhi ➡️ 9999965857 🚀 No Advance 24HRS...
VVVIP Call Girls In Greater Kailash ➡️ Delhi ➡️ 9999965857 🚀 No Advance 24HRS...Call Girls In Delhi Whatsup 9873940964 Enjoy Unlimited Pleasure
Falcon stands out as a top-tier P2P Invoice Discounting platform in India, bridging esteemed blue-chip companies and eager investors. Our goal is to transform the investment landscape in India by establishing a comprehensive destination for borrowers and investors with diverse profiles and needs, all while minimizing risk. What sets Falcon apart is the elimination of intermediaries such as commercial banks and depository institutions, allowing investors to enjoy higher yields.Falcon Invoice Discounting: The best investment platform in india for investors
Falcon Invoice Discounting: The best investment platform in india for investorsFalcon Invoice Discounting
Kürzlich hochgeladen (20)
VVVIP Call Girls In Greater Kailash ➡️ Delhi ➡️ 9999965857 🚀 No Advance 24HRS...
VVVIP Call Girls In Greater Kailash ➡️ Delhi ➡️ 9999965857 🚀 No Advance 24HRS...
Mysore Call Girls 8617370543 WhatsApp Number 24x7 Best Services
Mysore Call Girls 8617370543 WhatsApp Number 24x7 Best Services
Call Girls in Delhi, Escort Service Available 24x7 in Delhi 959961-/-3876
Call Girls in Delhi, Escort Service Available 24x7 in Delhi 959961-/-3876
Call Girls Ludhiana Just Call 98765-12871 Top Class Call Girl Service Available
Call Girls Ludhiana Just Call 98765-12871 Top Class Call Girl Service Available
Call Girls Zirakpur👧 Book Now📱7837612180 📞👉Call Girl Service In Zirakpur No A...
Call Girls Zirakpur👧 Book Now📱7837612180 📞👉Call Girl Service In Zirakpur No A...
The Path to Product Excellence: Avoiding Common Pitfalls and Enhancing Commun...
The Path to Product Excellence: Avoiding Common Pitfalls and Enhancing Commun...
Quick Doctor In Kuwait +2773`7758`557 Kuwait Doha Qatar Dubai Abu Dhabi Sharj...
Quick Doctor In Kuwait +2773`7758`557 Kuwait Doha Qatar Dubai Abu Dhabi Sharj...
Falcon's Invoice Discounting: Your Path to Prosperity
Falcon's Invoice Discounting: Your Path to Prosperity
Chandigarh Escorts Service 📞8868886958📞 Just📲 Call Nihal Chandigarh Call Girl...
Chandigarh Escorts Service 📞8868886958📞 Just📲 Call Nihal Chandigarh Call Girl...
Call Girls From Pari Chowk Greater Noida ❤️8448577510 ⊹Best Escorts Service I...
Call Girls From Pari Chowk Greater Noida ❤️8448577510 ⊹Best Escorts Service I...
FULL ENJOY Call Girls In Mahipalpur Delhi Contact Us 8377877756
FULL ENJOY Call Girls In Mahipalpur Delhi Contact Us 8377877756
Insurers' journeys to build a mastery in the IoT usage
Insurers' journeys to build a mastery in the IoT usage
Falcon Invoice Discounting: The best investment platform in india for investors
Falcon Invoice Discounting: The best investment platform in india for investors
Call Girls In Panjim North Goa 9971646499 Genuine Service
Call Girls In Panjim North Goa 9971646499 Genuine Service
How to Get Started in Social Media for Art League City
How to Get Started in Social Media for Art League City
Russian Call Girls In Gurgaon ❤️8448577510 ⊹Best Escorts Service In 24/7 Delh...
Russian Call Girls In Gurgaon ❤️8448577510 ⊹Best Escorts Service In 24/7 Delh...
Empfohlen
Empfohlen (20)
Product Design Trends in 2024 | Teenage Engineerings
Product Design Trends in 2024 | Teenage Engineerings
How Race, Age and Gender Shape Attitudes Towards Mental Health
How Race, Age and Gender Shape Attitudes Towards Mental Health
AI Trends in Creative Operations 2024 by Artwork Flow.pdf
AI Trends in Creative Operations 2024 by Artwork Flow.pdf
Content Methodology: A Best Practices Report (Webinar)
Content Methodology: A Best Practices Report (Webinar)
How to Prepare For a Successful Job Search for 2024
How to Prepare For a Successful Job Search for 2024
Social Media Marketing Trends 2024 // The Global Indie Insights
Social Media Marketing Trends 2024 // The Global Indie Insights
Trends In Paid Search: Navigating The Digital Landscape In 2024
Trends In Paid Search: Navigating The Digital Landscape In 2024
5 Public speaking tips from TED - Visualized summary
5 Public speaking tips from TED - Visualized summary
Google's Just Not That Into You: Understanding Core Updates & Search Intent
Google's Just Not That Into You: Understanding Core Updates & Search Intent
The six step guide to practical project management
The six step guide to practical project management
Beginners Guide to TikTok for Search - Rachel Pearson - We are Tilt __ Bright...
Beginners Guide to TikTok for Search - Rachel Pearson - We are Tilt __ Bright...
Poster Simply Targeting (HI DEFINITION)
- 1. CAMPAGNA BRAND 0%0% 0%0%0% 0% 0% 0% 0% 0% 100% 90% 75% 60% 45% 30% 10% Last 30 days CTR RANDOM CLUSTER YIELD 0,085 0,080 0,075 0,070 0,065 0,060 0,055 0,050 0,045 0,040 0,035 0,030 0,025 0,020 0,015 0,010 0,005 0,000 242,5 245,0 247,5 250,0 252,5 255,0 257,5 260,0 262,5 265,0 267,5 270,0 272,5 Last 30 days Ecpm RANDOM CLUSTER YIELD 0,16 0,15 0,14 0,13 0,12 0,11 0,10 0,09 0,08 0,07 0,06 0,05 0,04 0,03 0,02 242,5 245,0 247,5 250,0 252,5 255,0 257,5 260,0 262,5 265,0 267,5 270,0 272,5 Results We ran several tests to compare this methodology with competitors platforms and with non optimized impressions.We delivered the same campaigns on the same publishers and si- multaneously by three different delivery algorithms: 1. Our cluster yield method described in this paper / 2. A random non optimized method / 3. A competitor platform based on standard behavioural techniques We executed this test on different days and with different campaigns.We measured an average increase of conversion rate of 150% by the cluster yield method compared with non op- timized delivery.We measured an average increase of conversion rate of 60% by the cluster yield method compared with competitor platform Data-driven behavioural algorithms for online advertising Users Profiling For each user we are able to have information about advertising campaigns, web pages and search queries of interest. We analyze the top significant keywords as- sociated to the content he visited and we are able to extract those ones which have the highest occurency frequency across the corpus of documents. The User Profiling algorithms is then able to build a profile with selected keywords. Clustering Methods The User Similarity Matrix is used to apply an automatic K-Mean Clustering Algorithm. It would be computatio- nally difficult to cluster the huge amount of user profi- les built over Simply Network. As a consequence we developed the following clustering strategy: 1. We apply the clustering methods just on the most active users where for active we mean the fact that they clicked on advertising campaigns and/or launched search queries. 2. Once the clusters are built , we estimate a set of centroids 3. We then built a classification al- gorithm that estimates the di- stance between an user and the centroids of the different cluster and will assign the user to the best matching cluster 4. We classified all profiled users Cluster 30% Affinity percentage