Ibm info sphere datastage tutorial part 1 architecture examples
•
2 gefällt mir•5,370 views

data stage, IBM information Architecture, IBM data Stage Architecture, IBM InfoSphere datastage

Empfohlen
Weitere ähnliche Inhalte
Was ist angesagt?
Was ist angesagt? (20)
Andere mochten auch
Andere mochten auch (16)
Ähnlich wie Ibm info sphere datastage tutorial part 1 architecture examples
Ähnlich wie Ibm info sphere datastage tutorial part 1 architecture examples (20)
Mehr von Sandeep Sharma IIMK Smart City,IoT,Bigdata,Cloud,BI,DW
Mehr von Sandeep Sharma IIMK Smart City,IoT,Bigdata,Cloud,BI,DW (20)
Kürzlich hochgeladen
Kürzlich hochgeladen (20)
Ibm info sphere datastage tutorial part 1 architecture examples
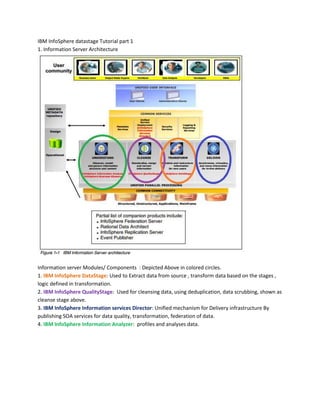
- 1. More Details blog:http://sandyclassic.wordpress.com linkedin:https://www.linkedin.com/in/sandepsharma slideshare:http://www.slideshare.net/SandeepSharma65 facebook:https://facebook.com/sandeepclassic google+ http://google.com/+SandeepSharmaa Twitter: https://twitter.com/sandeeclassic IBM InfoSpheredatastage Tutorial part 1 1. Information Server Architecture Information server Modules/ Components : Depicted Above in colored circles. 1. IBM InfoSphereDataStage: Used to Extract data from source , transform data based on the stages , logic defined in transformation. 2. IBM InfoSphereQualityStage: Used for cleansing data, using deduplication, data scrubbing, shown as cleanse stage above. 3. IBM InfoSphere Information services Director: Unified mechanism for Delivery infrastructure By publishing SOA services for data quality, transformation, federation of data. 4. IBM InfoSphere Information Analyzer: profiles and analyses data.
- 2. More Details blog:http://sandyclassic.wordpress.com linkedin:https://www.linkedin.com/in/sandepsharma slideshare:http://www.slideshare.net/SandeepSharma65 facebook:https://facebook.com/sandeepclassic google+ http://google.com/+SandeepSharmaa Twitter: https://twitter.com/sandeeclassic IBM Information Server Client Server Architecture: Client Tier: Creating managing, designing Jobs. Administrative Client: manage security, licensing, logging and scheduling, Server Tiers: 1. Services: Common services security, user administration, logging, reporting, metadata and execution. Product specific services: like Analyzer service. 2. Repository: Maintain Repository 3. Engine: parallel runtime Engine executes information server tasks. 4. Working Areas: Temporary Storage Areas.
- 3. More Details blog:http://sandyclassic.wordpress.com linkedin:https://www.linkedin.com/in/sandepsharma slideshare:http://www.slideshare.net/SandeepSharma65 facebook:https://facebook.com/sandeepclassic google+ http://google.com/+SandeepSharmaa Twitter: https://twitter.com/sandeeclassic Topologies: 2 tier, 3 tier, Cluster, Grid. The processing Engine is distributed across multiple tier cluster taking up load dynamically. While Client tier maintains client component , and Web server tier manage Web Server Components.
- 4. More Details blog:http://sandyclassic.wordpress.com linkedin:https://www.linkedin.com/in/sandepsharma slideshare:http://www.slideshare.net/SandeepSharma65 facebook:https://facebook.com/sandeepclassic google+ http://google.com/+SandeepSharmaa Twitter: https://twitter.com/sandeeclassic Data Transformation Stage Description Aggregation Consolidates aggregates data Basic Conversion Ensure data type are properly Converted and mapped Cleansing Data cleansing Derivation Transforming data from multiple sources using complex business Rule/algorithms. Enrichment Combining data from internal and external sources Normalizing Reducing redundancy or normalize data. Combining Lookup, join or merge operation Pivoting Converting input stream to multiple appropriate data marts. Sorting Sort records Source To Target job execution Parallelism Pipeline parallelis: data is processed send to target databases As soon as it is available or read from source rather than waiting for All data to read at once from source. Partition Parallelism: The data table is partitioned at source horizontally or vertically so multiple records can be read at once based on different partition set. Data is portioned using algorithm like Hash partitioning. Hash partitioning used hash key to distribute data across multiple data partitions(or subtables)
- 5. More Details blog:http://sandyclassic.wordpress.com linkedin:https://www.linkedin.com/in/sandepsharma slideshare:http://www.slideshare.net/SandeepSharma65 facebook:https://facebook.com/sandeepclassic google+ http://google.com/+SandeepSharmaa Twitter: https://twitter.com/sandeeclassic