1. Page 1
Se rvice
De sig n
Se rvice
ITIL
Service
Strategy
SERVICE
OPERATION
Service
Design
Continual Service
Improvement
Service
Transition
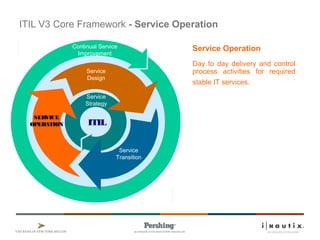
ITIL V3 Core Framework - Service Operation
Service Operation
Day to day delivery and control
process activities for required
stable IT services.
2. Page 2
Service Operation
SO will manage a service through its production life of day-to-day
management.
Main Target Audience:
– Service owners, operational staff, vendors and service providers.
Main Influencers:
–Customers, end users, business and IT Management
3. Page 3
Scope of Service Operation
Execution & Ongoing Activities
– Provided Services
Internal & External
– Service Management Processes
Service Operation & Other Lifecycle Processes
– Technology
Managing Technology
– People
Consumers of Services
Providers of Services
4. Page 4
SO – Value to the Business
Actual delivery of services
Relationship with and satisfaction of customers is improved
Provision of what is required by the business is provided and planned
for
From customer viewpoint, it is where actual value is seen.
5. Page 5
The Principles of SO
Balancing in Service Operation
It is necessary to achieve a balance between :
– Internal vs. External view
– Stability vs. Responsiveness
– Quality vs. Cost
– Reactive vs. Proactive
7. Page 7
Achieving Balance in SO
Internal View
– Used by IT to Manage the Delivery of Services
– Functional Technological Segmentation
– Functional Focus in Maximizing Its Technology
External View
– Services as Experienced by Users & Customers
– Little or No Appreciation of “Technological Elegance”
– Concerned with Quality of Service.
8. Page 8
Balancing Stability vs. Responsiveness
Stable & Available
– Technology
– Compliance
– Technology’s Gatekeeper
– As Long as it works with the Existing Technology
– Drives towards a “Steady State”
Business Needs Change
– Demand Outpaces the Thought Process
– New projects Siphon Resources From Existing Services
– Technology “Grab Bag”
– Disproportionate Consumption of Resources
– Take Care of the Future – Don’t Worry About Today
9. Page 9
Balancing QoS vs. CoS
Good, Fast or Cheap
– Pick Any Two
Cheap is Never the Least Expensive
Over-Delivering Doesn’t Ensure Quality
Balance is Optimization
– Bring Quality in Line With Value of the Service
Note: “Value” NOT “Cost”
– Quality Costs Less Early in the Lifecycle…..and More Later in the Lifecycle
10. Page 10
Balancing Reactive vs. Proactive
Reactive Organization – Waits for Stuff to happen
– Firefighting is a Way of Life
– Heroes Are Revered
Proactive Organization – Constantly Looking for Improvement
– Fire Prevention is a way of Life
– Heroes Are Acknowledged
Investigations Launched into What Went Wrong
11. Page 11
The Process of Service Operation
Incident Management
– Coordination of IT resources needed to restore an IT service
Event Management
– Monitoring events throughout the IT Infrastructure
Request Fulfillment
– Managing customer & user requests that are not the result of an incident.
Problem Management
– Finding the root cause of events & incidents
Access Management
– Granting authorized users the right to use a service.
13. Page 13
Incident Management
Goal
– To restore normal service operation as quickly as possible with minimum disruption to the
business, thus ensuring that the best achievable levels of availability and service are
maintained
Scope
– Incident management includes any Event which disrupts, or which could disrupt a service.
Eg. Hardware failure, Software error, Network faults, Performance issues, etc
– Incident reported ( or logged) by technical staff, tools, user(s), etc
Benefits
– Minimize the disruption and downtime for our users
– Maintain a record during the entire Incident life-cycle. (This allows any member of the service
team to obtain or provide an up-to-date progress report)
– Incidents are dealt with quickly, before they become severe.
– Building knowledgebase of known issues to allow quicker resolution of frequent Incidents
14. Page 14
Incident Management – Key Concepts
Incident : An unplanned interruption to an IT Service or a reduction in the
quality of an IT service
Impact : A measure of the effect of an Incident, problem or Change on
Business Processes.
Response Time : A measure of the time taken to complete an Operation
Resolution Time : The time that elapses between acknowledged receipt of
an incident and incident resolution.
Priority : A category used to identify the relative importance of an incident,
problem or change.
Hierarchical Escalation: Informing or involving more senior levels of
management to assist in an escalation
Functional Escalation: Transferring an incident, problem or change to a
technical team with a higher level of expertise to assist in an escalation.
15. Page 15
Incident Lifecycle
The progression of an incident through a standard process flow.
The key stages in the flow are:
Incident Detecting and Recording
Initial Classifcation and Support
Investigation and Diagnosis
Resolution and Recovery
Closure
16. Page 16
Incident Logging
Sources of Incidents
– Users
– Operations
– Network management
– Systems Management Tools
Record Incident Information
Alert Other IT Domains
– Operations
– Network Management
17. Page 17
Incident Categorization
Gather additional Information
– Key Data Elements
Classification Using
– Standard Coding Scheme
Match to Knowledge Base
– Previous Incidents
– Problems
– Know Errors
Assign Initial Priority
Escalate if Necessary
19. Page 19
Incident Priority
What Does It Do to the business?
– Business Impact
How Quickly Does it Have to Be Fixed?
– Business Urgency
Priority Assignment
– Function of Impact & Urgency
Priority = Urgency x Impact
Impact = Effort upon the Business
Urgency = Extent to which the resolution can bear delay.
20. Page 20
Impact
Impact is defined as the number of people affected by a service
outage.
Low Impact: One customer affected, where no executive or
executive staff are involved.
Medium Impact: Several customers are affected, or an executive or
executive staff are involved.
High Impact: Whole organization, complete department or building
affected, or revenue/financial systems affected
21. Page 21
Urgency
Urgency is defined as the affect of the event on a customer’s ability
to work.
Low Urgency: Ability not impaired, the customer is requesting extra
or additional functions or services (a service request).
Medium Urgency: Abilities are partially impaired, and customers
cannot use certain functions or services.
High Urgency: Abilities are completely impaired and customers
cannot work.
22. Page 22
Priority
Priority is based on Impact and Urgency. The priority determines how
quickly the issue needs to be addressed.
Low Priority: Work to be completed in 4 business days.
Medium Priority: Work to be completed in 2 business days.
High Priority: Work to be completed in 4 hours.
Urgent Priority: Work to be completed in 2 hours.
23. Page 23
Incident Priority
Priority = Urgency x Impact
Urgency = Extent to which the resolution can bear delay
Impact = Effort upon the Business
How quickly does it have to be fixed?
– Business Urgency
What does it do to the business?
– Business Impact
24. Page 24
Incident Class
Incident Class Description
Priority 1 (P1 Critical) Key production system/s failed or unavailable causing severe disruption to
primary business operations.
Priority 2 (P2 High) A critical system/s failed or unavailable causing disruption and impact to critical
business operations. No reasonable workaround available in terms of risk,
effort and customer impact.
Priority 3 (P3 Medium) Some production system/s and or functions are degraded causing medium
impact. A reasonable workaround is available but a permanent solution is
required.
Priority 4 (P4 Low) Some system functionality has failed or is unavailable with minimal
inconvenience to users. Business disruption is minimal and a workaround is
available. A permanent solution is required.
25. Page 25
Response & Resolution times for Incidents
Response Time Resolution Time
Incident Priority
During regular
support hours
During on call
support hours
During regular
support hours*
During on call
support hours*
Priority 1 15 min. ½ hour 4 hours 4 hours
Priority 2 1 hour 4 hours 6 hours 8 hours
Priority 3 4 hours N/A 3 w/days N/A
Priority 4 1 w/day N/A As agreed N/A
27. Page 27
Incident Diagnosis
Coordinate Activities
– Investigation
– Diagnosis
Escalation
– Functional
– Hierarchical
Coordinate Development of a Workaround
Iterative Process
– Keep User Informed
28. Page 28
Incident Escalation
2nd
Line
Support
Team
3rd Line
Support
Team
Service Desk
Manager
Service
Desk
Support
Team
3rd
Line
Manager
2nd
Line
Manager
IT Service
Manager
Functional (competence)
Hierarchical(authority)
Functional
– First Level to Second Level to
third level, Etc.
– Increased Requirements for
Technical Expertise
– Often Based on Elapsed Time to
avoid a Service Level Breach
Hierarchical
– When Resolution is Not Likely in
Time to Avoid a Service Level
Breach
– Inform in Advance so Timely
Action can be taken
– Allows Time for Corrective Action
29. Page 29
Escalation Process for Incident Management
Escalation level Name and Designation
Level 1 Service IT
Level 2 Chennai Messaging Team
Level 3 Manager
Level 4 Group Manager
Below chart shows the timelines for escalation for incidents after the defined
resolution time has expired.
Severity Level 1 Escalation Level 2 Escalation Level 3 Escalation Level 4
Escalation
Priority 1 (Critical) 0 Hour** 1/2 Hour 1 Hour 2 hours
Priority 2 (High) 1 Hour 4 Hours 8 Hours 2 w/days
Priority 3 (Medium) 1 w/day 2 w/days 5 w/days N/A
Priority 4 (Low) 3 w/days 5 w/days N/A N/A
30. Page 30
Incident Resolution & Recovery
Matches to Knowledge Base
– Problems
– Known Errors
Clean Up / Restore Service
– Restore Files
– Boot Server
Update Incident Record
Raise RFC?
31. Page 31
Incident Closure Activity
Incident Review
– Review the Incident against Known Errors problem, solutions, planned changes or
knowledge base
Final Classification
– Standard Coding Scheme
– Enables Quality Analysis
Restricted Authority
– Reduced Temptation to “Edit History”
33. Page 33
Incident Management – CSFs & KPIs
Critical Success Factors :
– Maintaining IT Service Quality
– Maintaining Customer Satisfaction
– Resolving Incidents within established Service Times
Key Performance Indicators:
Maintaining IT Service Quality
– Number of Severity 1 incidents (total and by category)
– Number of Severity 2 incidents (total and by category)
– Number of other incidents (total and by category)
– Number of incidents incorrectly escalated
– Number of incidents bypassing Service Desk
– Number of incidents not closed/resolved with workarounds
– Number of incidents reopened
34. Page 34
Incident Management – CSFs & KPIs
Maintaining Customer Satisfaction
– Number of User/Customer surveys sent
– Number of User/Customer surveys responded to
– Average User/Customer survey score (total and by question
category)
– Average queue time waiting for Incident response
Resolving Incidents Within Established Service Times
– Number of incidents logged
– Number of incidents resolved by Service Desk
– Number of incidents escalated by Service Desk
– Average time to restore service from point of first call
– Average time to restore Severity 1 incidents
– Average time to restore Severity 2 incidents
35. Page 35
Incident Management Reports
Incident Management reports may include:
– Size of current Incident backlog
– Number and percentage of Major Incidents
– Percentage of Incidents handled within agreed resolution time.
– Number and percentage of Incidents incorrectly assigned
– Number and percentage of Incidents incorrectly categorized.
36. Page 36
Incident Management - Roles
Incident Manager
– Manages Work of Incident Support Staff
First Line Support
– Normally the Service Desk
Second Line Support
– Generally Higher Technical Skills
Third Line Support
– Internal Technical Support
– Third-party Support
37. Page 37
Incident Management - Challenges
Incident must be detected as early as possible
Convince all staff that all Incidents must be logged
Availability of information about Problems and Known Errors, workarounds.
Integration into the Configuration Management System
Integration into the Service Level management process
38. Page 38
Event Management
Purpose:
– Provides the basis for Operational Monitoring & Control
Goal :
– Monitor all events to enable the achievement of normal operation.
Objectives :
– Detect, analyze & direct appropriate control actions.
39. Page 39
Importance of Event Management
The ability to monitor and decipher the continuous flow of information about
the status of service components is key.
Formal Event Management detects fluctuations in component and service
performance, which can be tuned dynamically to suit each condition.
Provides the ability to detect events, make sense of them
Can be used as a basis for automating many Operations Mgt activities, e.g.
Executing scripts on remote devices, submitting jobs for processing
Provides an entry point for execution of many Service Operation processes &
activities
Provides:- monitoring of SLA’s; basis for Service Assurance & Reporting, and
Service Improvement
40. Page 40
Event Management – Key Concepts
Event - Any detectable occurrence in the IT infrastructure.
Monitoring - Monitoring refers to the activity of observing a
situation to detect changes that happen over time
Reporting - Reporting refers to the analysis , production
and distribution of the output of the monitoring activity
Alert - A threshold has been exceeded
Event correlation - To understand events they are
analyzed against other events and their configuration items
Event filtering - Filtering decides if the event is
informational, warning or exception
– Event Information - no action required ( An IT user may
be logging on to a system)
– Warning - A threshold is soon to be reached or
unauthorized IT event has occurred (An IT user is using
unauthorized software)
– Exception - Typically a configuration item acting
abnormally or a new configuration item has been
implemented (An IT user is logged onto a system where
memory seems to be filling up too quickly)
41. Page 41
Event Management – Desirable Tool Features
Multi-environmental, open interface to allow monitoring across heterogeneous services
& entire IT infrastructure
Easy to deploy, with minimum setup costs
‘Standard Agents’ to monitor most common components/systems
Open interfaces to accept any standard e.g. SNMP event input
Centralised routing of all events to a single location programmable to allow different
location(s) at various times.
Support for design/test phases
Programmable assessment and handling of alerts depending on symptoms & impact
Ability to allow an operator to acknowledge an alert, or if no response then
automatically escalate
Good reporting functionality to allow feedback into design & transition phases as well as
meaningful management info & and business user dashboard
42. Page 42
Event Management Roles
The Role of the Service desk
– Initial Support, Escalation, Communications
Role of Technical and Application Management
– Define, Manage Events
– Deal with Incidents and Problems related to Event
IT Operations Management
– Event Monitoring, provide initial response
43. Page 43
Request Fulfillment
Purpose :
– Manage non-incident related customer or user requests
Goal :
– Facilitate the timely and accurate fulfillment of request for service
Objective :
– Deliver requested pre-approved standard services.
44. Page 44
Request Fulfillment Roles
Service Desk Staff
– Service Desk and Incident Management staff provides initial response and handles the request
Staff in other appropriate functions
– Responsible for ensuring eventual fulfillment of the request.
External Suppliers, as appropriate
– As per the request from the organizations, fulfill the Service Request.
45. Page 45
Problem Management
Goal
– To minimize the adverse effect on the business of incidents and problems caused by errors in the infrastructure,
and to proactively prevent the occurrence of incidents, problems and errors
Scope
– Identify and resolve IT problems that affect IT services
To minimize the impact of problems and incidents
– Pro-active problem management
To reduce the overall number of IT incidents
– Maintain information about problems and the appropriate workarounds and resolutions
– To ensure that the right level and number of resources are resolving specific problems
– Maintaining relationships with third party suppliers
Benefits
– Identifies and escalates a problem to the highest priority.
– Ensures involvement by appropriate staff involved in providing any aspect of the service affected.
– Ensures that all possible causes are explored.
– Provides needed communication and follow up to ensure resolution.
– Learning from experience – the process provides historical data to identify trends, the means of preventing
failures and of reducing the impact of failures
46. Page 46
Problem Management – Key Concepts
Problem :
– “The unknown root cause of one or more Incidents”
Workaround :
– “ A temporary way of overcoming technical difficulties (i.e., Incidents or problems”)
Known Error
– “ Problem that has a documented Root Cause and a workaround”
Known Error Database (KEDB)
– “Database containing all Known Error Records”
47. Page 47
Problem Management
ProblemsIncidents
}
}
}
Known Errors Request for Change
}
}
}
• How well does IT respond to
incidents?
• How much does it cost?
• Are all incidents logged and
tracked?
• How is customer satisfaction?
• What % of incidents are
studied for root causes?
• How many FTE?
• How quickly is it done?
• How much does it cost?
• How good are we?
• How much does it cost to id
a root cause? How many
FTE?
• What % of problems have
identified root causes
• How many incidents were caused by
changes?
• How many changes of each type?
• How much do they cost?
• How many root causes were
eliminated and what % of incidents
does that represent?
48. Page 48
Difference between Incident and Problem Management
Incident Management
– Restores agreed levels of service
– Uses workarounds
Incidents and Service Requests are formally managed through a staged process to conclusion.
This process is referred to as the "Incident Management Lifecycle".
The objective of the Incident Management Lifecycle is to restore the service as quickly as possible
to meet Service Level Agreements.
The process is primarily aimed at the user level.
Problem Management
– Diagnoses the root cause of incidents
– Identifies a permanent solution
– May take longer than Incident Management
Problem Management deals with resolving the underlying cause of one or more Incidents. The
focus of Problem Management is to resolve the root cause of errors and to find permanent
solutions.
Although every effort will be made to resolve the problem as quickly as possible this process is
focused on the resolution of the problem rather than the speed of the resolution.
This process deals at the enterprise level.
50. Page 50
Problem Management Activities
The main activities involved in Problem Management are:
Problem Control
– Its responsible for logging and classifying problems to determine their causes and turn them
into known errors.
Error Control
– records known errors and proposes solutions to them by means of RFCs which are
sent to Change Management. It also conducts Post-Implementation Review of
these changes in close collaboration with Change Management.
Proactive Problem Management
– Analysis of trends from incident records provides view on potential problems before they occur
51. Page 51
Problem Control
The main objective of Problem Control is to turn problems into Known
Errors so that Error Control can propose the relevant solutions.
Problem Control basically consists of three phases:
1. Identification and Logging
2. Classification and Allocation of Resources.
3. Analysis and Diagnosis: Known error
52. Page 52
Problem Control
1. Identification and Logging
– One of the main tasks of Problem Management is to identify problems. The main sources of
information used are:
The incident database
Analysis of IT infrastructure
Service Level Degradation
2. Classification and Allocation of Resources.
– Problems are classified according to their general characteristics, such as whether they are
hardware or software problems, the functional areas affected and details of the various
configuration items (CIs) involved.
3. Analysis and Diagnosis: Known error
– The main objectives of the process of analysis are:
Determining the causes of the problem.
Providing work-arounds for Incident Management to minimise the impact of the problem until the
necessary changes are made so as to resolve the problem definitively.
53. Page 53
Error Control
Once Problem Control has determined the causes of a problem, Error
Control is responsible for logging it as a known error.
– Error identification and recording
faulty CI is detected, and known error status is assigned.
– Error assessment
initial assessment of means required to solve the problem and raising of an RFC.
– Recording error resolution
solution for each known error should be in the PM system, made available for incident
matching
– Error closure
After successful implementation of the change, the error is closed together with all
associated Incident records.
– Monitoring problem and error resolution progress
Change management is responsible for implementing RFCs, but error control is responsible
for monitoring progress in resolving known errors.
54. Page 54
Proactive problem management
Problem Management may be:
Reactive: Analysing incidents that have occurred in order to discover their causes
and propose solutions to them.
Proactive: Monitoring the quality of the IT infrastructure and analysing its
configuration in order to prevent incidents even before they happen.
Proactive problem management activities are concerned with identifying and
resolving problems and known errors before Incidents occur
Trend analysis
identify “fragile” components and their reason. Requires availability of sufficient historical data.
– Targeting support action
towards problem areas requiring most support time, or causing most impact to the business (volume of
incidents, number of users impacted, cost to the business).
– Providing information to organization
Providing insight in effort and resources spent by organization in diagnosing and resolving problems and
known errors to management. Also information on workarounds, permanent fixes, and status information
should be given to Service Desk.
55. Page 55
Problem Management - Reporting
Items that can be reported to IT management
– Time spent on research and diagnosis
– Brief description of actions taken
– Planning unresolved problems with regard to use of people, use of tools, and costs
– Problems categorized into: status, service, impact, category, user group
– Turnaround time of closed problems
– Elapsed time and expected resolution period for unresolved problems
– Temporary corrective actions
Items that are important for Service Level Management
– Number of problems categorized into: user group, category, impact, service
– Turnaround time of closed problems
– Expected solution period for unresolved problems
Items that are important for Service Desk
– Status of problems
– Information on bypasses
56. Page 56
Service Desk – IM – PM (PC) (EC) - CM
User
Incident
DB
Problem
DB
Known Error
DB
Business Case
to FIX
Raise
RFC
ERROR CONTROL
PROBLEMCONTROL
Known Error
One or More Incidents with
Unknown Underlying cause
Root Cause Known and Temp or Perm Fix found
STOP
NO
YES
Change Management
Incident
PM
PM
PM
SD/IM
IM
57. Page 57
Problem Management CSFs & KPIs
Critical Success Factors
Avoiding Repeated Incidents
Minimizing Impact Of Problems
Key Performance Indicators
Avoiding Repeated Incidents
– Number of repeat incidents
– Number of existing Problems
– Number of existing Known Errors
Minimizing Impact of Problems
– Average time for diagnosis of Problems
– Average time for resolution of Known Errors
– Number of open Problems
– Number of open Known Errors
– Number of repeat Problems
– Number of Major Incident/Problem reviews
58. Page 58
Access Management
Goal :
– To grant authorized users the right to use a service, while preventing access to non-
authorized users.
Scope:
– Execute the policies & actions defined by Security & Availability.
Benefits
59. Page 59
Access Management – Basic Concepts
Access
– Refers to the level and extent of a Service’s functionality or data that a user is entitled to use.
Identity
– Information about a user that distinguishes them as an Individual, and which verifies their status within the
organization. By definition, the Identity of a user is unique to that user.
Rights ( or Privileges)
– Refers to the actual settings whereby a user is provided access to a Service or group of Services. Typical rights,
or levels of access include read, write, execute, change, delete.
Service or Service Groups
– Ability to grant each user (or group of users) access to the whole set of Services tat they are entitled to use at
the same time.
Directory Services
– A specific type of tool that is used to manage access and rights.
60. Page 60
Access Management Activities
Requesting Access
– Request for access could be a Request for Change (RFC) into the Change Management
System (Service Transition) or a Service Request from the Request Fulfillment System (Service
Operation).
– The Security policies will define which areas and departments may request access, and the
Access Management process will design the mechanisms to carry out that request.
Verification
– The verification activity verifies a request for access to ensure that the user requesting the
access is who he/she says he/she is, and that the user has a legitimate requirement for the
service.
– Depending on the levels of risk to the organization, the Security policies may define different
levels of verifications to access different services.
Providing Rights
– Once it has verified a user, Access Management provides the appropriate rights to him/her.
– The Security policy defines the rights that should be available to an individual, and Access
Management grants rights based on this information.
61. Page 61
Access Management Activities (Cont)
Monitoring Identity Status
– One of the problems with many manual Access Management systems in use today is that there
is no easy way to monitor when a user changes roles or Identity Status.
– Typical events that trigger a change in Identity Status are job changes, promotions or
demotions, transfers, resignation or death, retirement, disciplinary action, dismissals.
Logging and Tracking Access
– All Technical and Application Management monitoring activities should include reviews of
Access rights and utilization to ensure that the rights are being properly used.
– The review should direct all exceptions to Incident Management for investigation
Removing or Restricting Rights
– Users do not stay in the same jobs or roles forever, and neither should their access rights.
– This is another place to set up standard procedures and policies to more easily identify events
requiring the removal or restriction of rights.
62. Page 62
Access Management Roles
Information Security Managers
– Define and Maintain Policies for this process
Service Desk Staff
– Handle the Requests
Staff in other functions (e.g., Technical and Application management)
– Execution of the requests
63. Page 63
Functions of Service Operations
Service Desk
Technical Management
Application Management
IT Operations Management
64. Page 64
Service Desk
Goal
– To act as the Single Point of Contact (SPOC) between the User and IT Service
Management
– To handle Incidents and request and provide an interface for other activities such
as
Change Management
Problem Management
Configuration Management
Release Management
Service Level Management
IT Service Continuity Management
Benefits
– Improved User service, perception and satisfaction
– Increased User accessibility via the single point of contact
– Improved quality and faster response to User requests
– More effective and efficient use of support resources
– Better management information to make decision on support
65. Page 65
Service Desk - Objectives
Logging ALL Incidents & Request
First Line
– Investigation & Diagnosis
Incident & Request Resolution
Functional and Hierarchal Escalation
Customer Communication
– Incident Progress
– Pending Changes ( Forward Schedule of Changes)
– Agreed Outages ( Projected Service Availability)
Satisfaction Surveys
66. Page 66
Service Desk
Call Center
– To handle large volumes of telephone based transactions like telesales or order
processing
Help Desk
– To manage and resolve incidents quickly and effectively, and to make sure all
requests are followed up
Service Desk
– To extend beyond the range of services offered by the HD to allow business
processes to be integrated into Service Management infrastructure
– In addition to handling incidents, to provide an interface for managing changes,
SLM, maintenance issues, software licensing, IT Service Continuity Management,
Financial, Availability and Configuration Management
All three organizations share these characteristics:
– They aim to achieve customer satisfaction
– They use technology, people and processes to provide a service to the business
67. Page 67
Service Desk - Objectives
Logging ALL Incidents & Request
First Line
– Investigation & Diagnosis
Incident & Request Resolution
Functional and Hierarchal Escalation
Customer Communication
– Incident Progress
– Pending Changes ( Forward Schedule of Changes)
– Agreed Outages ( Projected Service Availability)
Satisfaction Surveys
68. Page 68
Setting up a Service Desk
Understand the business needs and requirements
Define clear objectives
Obtain support, budget and resources
Advertise and sell benefits / communicate quick wins
Involve and educate users / train support staff
69. Page 69
Service Desk – Organizational Structures
Local Service Desk
– Co-located with User Community
Centralized Service Desk
– Consolidation of Fewer or Single Service Desk
Virtual Service Desk
– Support Staff Geographically Dispersed
Follow the Sun
– Two or More Geographically Dispersed Service Desks
Specialized Service Desk Groups
– Direct Access to Technical Functional Specialist
70. Page 70
Local Service Desks
Designed to support local business needs
Support is usually in the same location as the business it is supporting
Practical for smaller organizations
72. Page 72
Central Service Desk
Designed to support multiple locations
Service Desk is in a central location while the business is distributed
Ideal for larger organization/economies of scale:
– Reduces operational costs
– Improves resource usage
Could provide secondary support to local desks
74. Page 74
Virtual Service Desk
Location of Service Desk analysts is invisible to the customers
Common processes and procedures should exist – single
incident log
Common agreed language for data entry
Single point of contact per customer
On-site presence may still be needed for some functions
“Workload partitioning” needed
76. Page 76
“Follow the Sun” Option
Not a type of Service Desk but an option usually applied to two
or more Central Service Desks for global operations
Where Service Desk support switches between two or more
desks to provide 24 hr global cover.
Telephony switching needed
Multilingual staff usually required
Local conditions and cultural issues need to be considered
Clear escalation channels needed
77. Page 77
A Self-Service Strategy
Gives some control to Customers, optionally:
– Log new incidents, change requests
– Self-help
– Order good or services
Can reduce work load on Service Desk
Particularly useful “out of hours” and for non-critical activities
Dependant on a strong knowledge base
78. Page 78
Outsourcing the Service Desk
Potential Benefits
– Financial savings
– Economies of scale
– Access to large skill pool
– Improved staff and service cover
– Competitive marketplace
Care Needed
– Viewing the Service Desk as an overload is damaging
– SD is the “window of service and professionalism”
– Intellectual capital should be protected
– Seek “vendor partnerships” and long-term relationships
79. Page 79
Service Desk - Staffing
Staffing Levels
– Based on Business Requirements
– Customer Service Expectations
Skill Levels
– Interpersonal
– Business Awareness
– Communication
– Technical Awareness
Training
– New Service Introduction
– Business Awareness
Retention
– Learning Organization
– Team Building
Support Users
– User Liaison to Filter Requests
80. Page 80
Service Desk - Metrics
First Line Resolution
Average Time to Resolve
Average Time to Escalate
Cost Per Incident/Request
Customer Updates Completed on Time
Incident/Request Volumes
– Hour of Day
– Day of week
– Week of Month
81. Page 81
Technical Management
Technical management is involved in all aspects of the Service Lifecycle.
Its activities include :
– Acquire and maintain require technical expertise
– Skills documentation
– Initial and on-going skills training
– Design and delivery of user training
– Standard definition
– Service Design
– Project Staffing
– Testing
– Service Transition (change, release & deployment)
– Continual Service Improvement
– Service Operation
– Diagnosis and recovery from technical failures.
82. Page 82
Technical Management
Role:
– Custodian of Technical Knowledge
– Support Resources to the ITSM Lifecycle
Objectives
– Participate in Planning, Implementation & Maintaining a Stable Technical
Infrastructure.
83. Page 83
Application Management
Application management has the overall responsibility for managing
applications throughout their lifecycle.
It may involve a number of different application development groups.
Its objective is to design of cost-effective applications that meet the
needs of the business customer in support of their business process.
Delivery of the required features and functionality needed to provide
the utility and warranty required.
Maintenance of software applications is very important to the overall
quality of the services provided.
84. Page 84
Application Management
Role :
– Custodian of Application Management
– Support Resources to the ITSM Lifecycle
Objective
– Well Designed, Resilient & Cost Effective Applications
– Deliver Required Functionality
– Demonstrate Technical Expertise in Maintenance
85. Page 85
IT Operations Management
Operations Management includes the functional groups involved in
day-to-day operational activities
Operation Control oversees and monitors the operational activities in
the IT infrastructure
Facilities Management manages the physical IT environment
Its objective is to ensure IT service is achieved and maintained
It is responsible for the optimization of support costs
86. Page 86
IT Operations Management
Role:
– IT Operations Control
Maintain stability of day-to-day processes and activities
– Facilities Management
Management of Physical IT environment, usually data centers or computer rooms.
Objectives
– Achieves & Maintain Stability
– Improve Service & Reduce Costs
– Demonstrate Responsiveness to Operational Failures
87. Page 87
IT Operations Management
IT Operation Management
IT Operation Control
Console Management
Job Scheduling
Backup and Restore
Print Na Output
Maintenance activities
Facilities Management
Data Centre
Computer Rooms
Recovery Sites
Power and air conditioning
Fire and security systems